Im letzten Blogpost habe ich die für Unity vorgefertigten Skripte AkEvent und AkTriggerEnter beschrieben, die in Kombination für das Auslösen von Wwise-Events genutzt werden. Dieses Mal möchte ich einige grundlegende Skripte zur Nutzung von Wwise vorstellen.
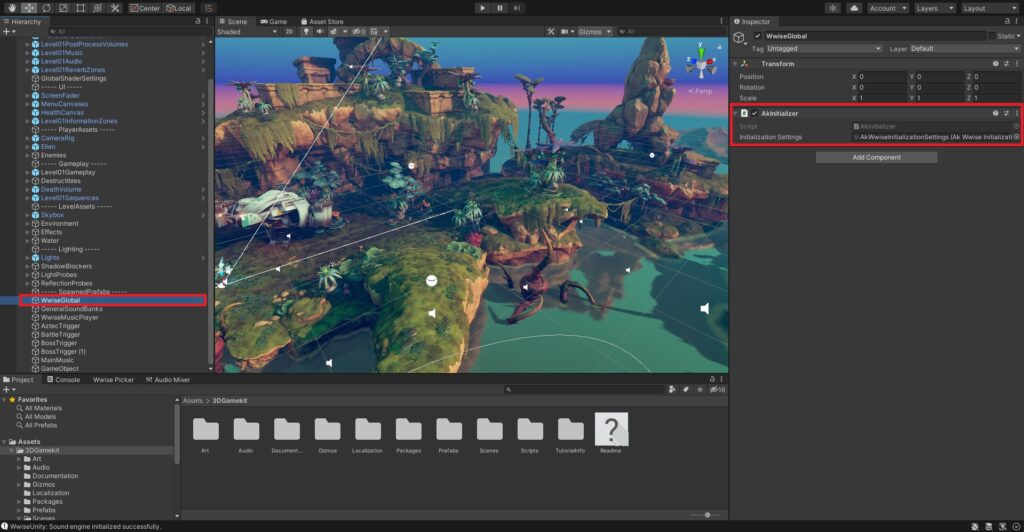
Damit die Unity-Engine allerdings überhaupt erkennt, dass es Wwise als Audio-Engine nutzen soll, muss zunächst Wwise beim Spielstart initialisiert werden. Das wird mit dem Skript AkInitializer realisiert. Hierfür wird ein leeres GameObject benötigt, das beim Starten des Spiels bereits vorhanden ist. Das GameObject wird im Inspector von Unity mit dem AkInitializer-Skript versehen, das automatisch beim Starten des Spiels geladen wird. Während des Spiels sorgt das Skript zusätzlich dafür, dass Frame für Frame Daten an die Wwise-Engine übetragen werden und somit die Kommunikation unter den beiden Engines gewährleistet wird. Das ist eine der Grundvoraussetzungen für die Nutzung von Wwise.
Leeres GameObject (links) mit AkInitializer-Skript (rechts)
Eine mit AkInitializer nah verwandte Funktion von Wwise ist das Laden von sogenannten Soundbanks. Soundbanks sind Audiodaten und Befehle, die während des Spiels in den Arbeitsspeicher geladen werden und somit unmittelbar ohne längeren Wartezeiten abgerufen werden können. Große Spiele arbeiten mit vielen Soundbanks, die abhängig von der Position des Spielers oder anderen Bedingungen einzeln geladen und wieder entladen werden. Das ermöglicht die Realisierung von großen und komplexen Spielwelten auf einem PC oder einer Konsole. Häufig wird vom Entwicklerteam ein Datenmengenlimit vorgegeben, welches das Audio-Team nicht überschreiten darf.
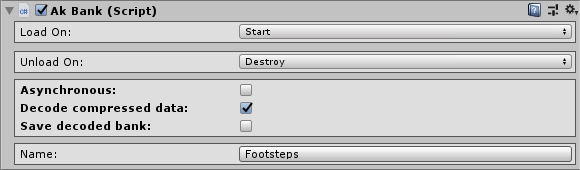
Das Skript für das Laden von Soundbanks heißt AkBank und kann an unterschiedlichen Stellen ausgeführt werden. In der Regel hat man immer eine Soundbank, die beim Starten des Spiels geladen wird. Weitere Soundbanks werden unter anderem geladen, wenn ein neues Gebiet betreten wird. Das Laden einer Soundbank dauert eine Weile, weshalb einige Spiele währenddessen eine Ladesequenz anzeigen. Bei der praktischen Anwendung erfordert das Skript im Unity-Inspector eine Information, wann die Soundbank geladen, wann sie entladen werden soll. Dabei muss auch bestimmt werden, welche Soundbank geladen werden soll. Es gibt noch weitere Optionen, mit welchen sich einstellen lassen, wie dekodiert und wie genau mit den Daten verfahren werden soll. Das hilft beim Datenmanagement und ist vor allem für umfangreiche Spiele mit großen Datenmengen praktisch.
Die Soundbank “Footsteps” wird beim Starten des Spiels geladen und beim Zerstören des GameObjects entladen
Es gibt verschiedene Methoden Wwise-Elemente in der Gameengine Unity zu implementieren. Zum einen gibt es es die klassische manuelle Implementierung mithilfe von Skriptbefehlen in den Programmiersprachen C# (am populärsten), UnityScript und Boo zum anderen gibt es auch vorgefertigte Skripte (in C#) und Funktionen, die ein schnelles Implementieren innerhalb des Unity-Editors ermöglicht.
Vorgefertigte Skripte
Diese Skripte werden bei der Installation von Wwise in einem Unity-Projekt mitgeliefert und decken eine allgemeine Bandbreite von unterschiedlichen Implementierungsmöglichkeiten ab.
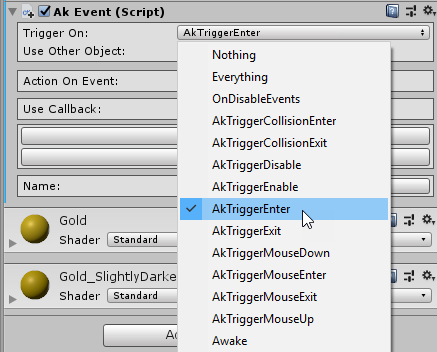
Eine der am häufigsten benötigten Funktionen bei der Nutzung von Wwise-Elementen ist das Abrufen von Wwise-Events. Diese übermitteln Informationen an Wwise, die Anweisungen, wie die Audio-Engine handeln soll, beinhalten. In den meisten Fällen ist es das Abspielen oder Unterbrechen von Sounds. Das für Unity vorgefertigte Skript heißt AkEvent. Dieses ist an Bedingungen geknüpft. Häufig ist es das Betreten oder Verlassen eines GameObjects, wie z.b. eines Colliders. Ein Collider ist eine geometrische Form (häufig unsichtbar für den Spieler) im Spiel, die für das Triggern verschiedener Funktionen genutzt werden kann.
AkEvent, das auf das Betreten des Triggers ausgeführt wird
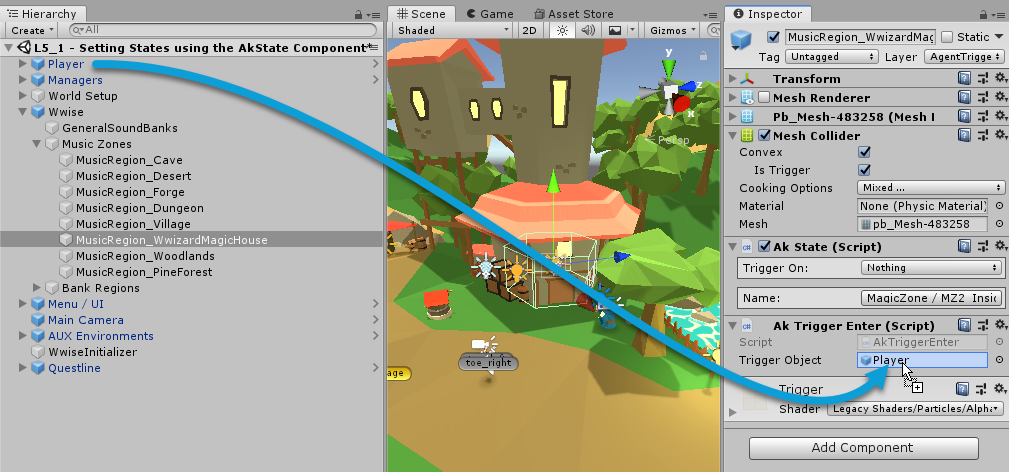
Zusätzlich muss dabei erwähnt werden, dass Collider nur auf GameObjects reagieren. In der Regel möchte man allerdings spezifizieren, welche GameObjects genau diese Trigger auslösen können, sonst reagieren die Trigger auf jedes Eintreten irgendeines GameObjects, also auch auf Elemente, wie überlappende Bausteine aus der Spielwelt. Mit dem Skript AkTriggerEnter kann man festlegen welches GameObject diesen Trigger auslösen kann. Häufig soll nur die eigene Spielfigur, die der Spieler steuert, triggerfähig sein.
AkTriggerEnter mit dem “Player” als einziges GameObject, das diesen Trigger auslösen kann
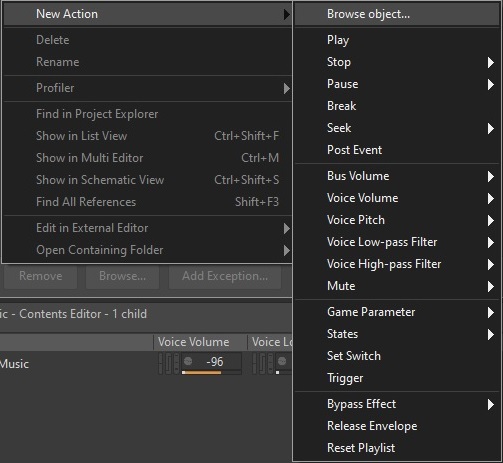
Eine der wichtigsten Funktionen der Middleware Wwise sind die sogenannten Events. Das sind unterschiedliche Anweisungen, die zur Steuerung von Audiodateien dienen. Zu den häufigsten Anwendungen gehören vor allem das Abspielen, Pausieren und Filtern von Audiodateien.
Auswahl an Aktionen, die in einem Event ausgeführt werden können
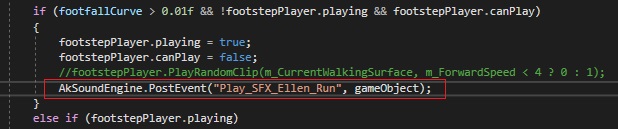
Zudem dienen Events auch als Bindeglied der jeweiligen Game Engine und der Audio Engine Wwise. Durch sogenannte Game Calls, die von der Game Engine an die Audio Engine geschickt werden und Events aufrufen, erkennt Wwise, dass Audiodaten verarbeitet werden sollen. Diese Game Calls werden im Programmcode an der passenden Stelle eingefügt. Dabei muss beachtet werden, dass die Schreibweise des Eventnamens mit dem String (Zeichenkette in einer Programmiersprache) im Programmcode übereinstimmt.
An dieser Stelle wird das Event Play_SFX_Ellen_Run aufgerufen
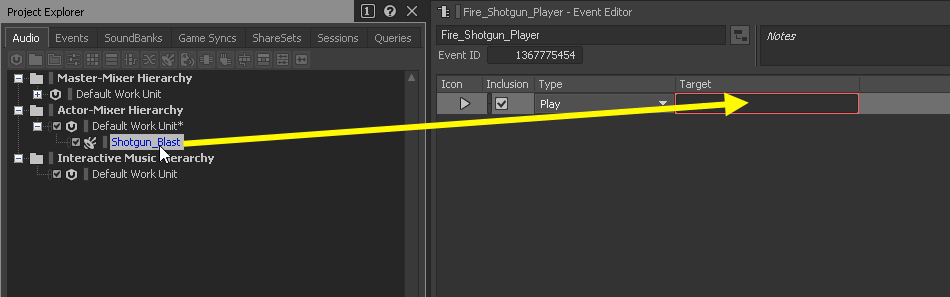
In Wwise können Events sowohl einzelne Soundeffekte aufrufen als auch ganze Wwise-Container. Dabei wird im Target-Feld des Event Editors der jeweilige Soundeffekt oder Container aus der Actor-Mixer Hierarchy ausgesucht. Dieser wird dann in Kombination mit der Anweisung (Type) aufgerufen.
Shotgun_Blast Soundeffekt wird im Event Fire_Shotgun_Player abgespielt
Als Sounddesigner und Musikschaffender ist es wichtig Werkzeuge zu haben, mit welchen Ideen möglichst einfach und schnell zu realisieren sind. Synthesizer sind oft komplexe Geräte, die einen Laien schnell überfordern können und lange Lernkurven haben. Selbst für erfahrene Nutzer sind viele Synthesizer oft nicht sehr intuitiv zu bedienen bzw. müssen aufwendig, teilweise durch langes Probieren, konfiguriert werden, um einen gewünschten Sound zu erzielen.
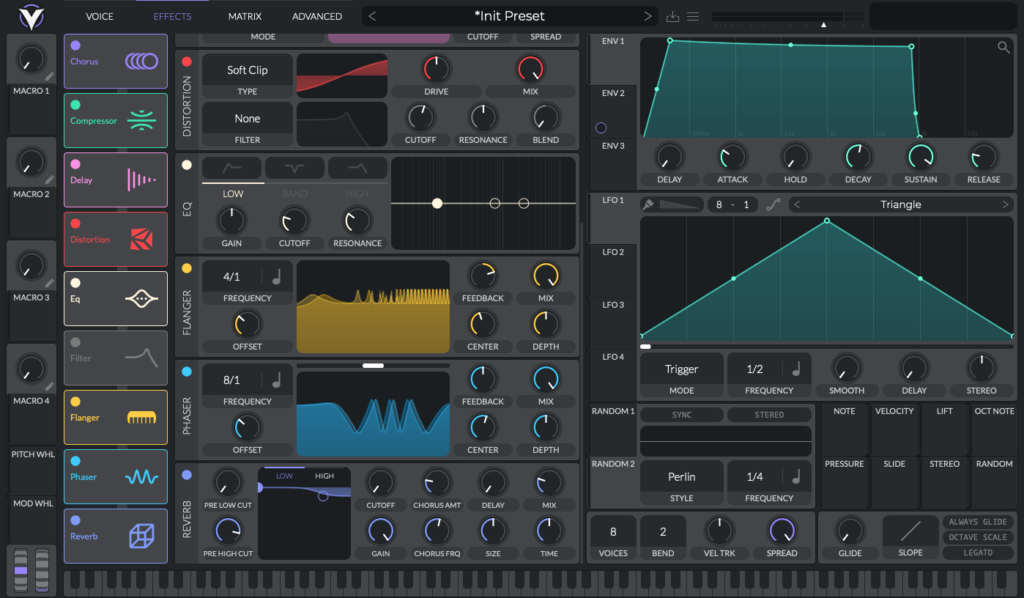
Vor kurzem ist allerdings der kostenlose Software-Synthesizer Vital veröffentlicht worden, der einen starken Fokus auf intuitive Benutzung legt und somit auch einsteigerfreundlich ist. Er ist jedoch auch hinsichtlich seiner Features sehr vielseitig einsetzbar ist und deckt ein breites Spektrum an Synthesemöglichkeiten ab. Die äußerst einfache Bedienung wird vor allem durch das gute User Interface ermöglicht. Obwohl dieser Synthesizer sehr viele verschiedene Funktionen hat, die auch in die Tiefe gehen, ist das Interface relativ simpel und logisch gestaltet. Hierzu muss man sagen, dass Vital stark vom Synthesizer Serum inspiriert wurde, der sich in den letzten 10 Jahren als einer der populärsten Synthesizern in der Produktion von elektronischer Musik etabliert hat. Beim ersten Öffnen des Plugins fällt ganz besonders auf, dass alle Elemente dieses Synthesizers grafisch so dargestellt werden, dass man sie leicht versteht. Sowohl die Wellenformen der Oszillatoren, als auch die Verläufe der Envelopes und LFOs bis hin zu der Form der Filterkurven werden alle auf einem Bildschirm visualisiert.
Komplexer Patch grafisch anprechend und logisch dargestellt
Die Oszillatoren bieten unterschiedliche Wellenformen: Von der einfachen Sinusschwingung bis zu komplexen Wavetables, die man selbst erstellen oder importieren kann. Sogar eine Text-To-Speech Funktion gibt es, die ein Wort oder einen Satz in verschiedenen Sprachen als Wavetable speichert und abspielt. Die Oszillatoren kann man zusätzlich noch untereinander mit verschiedenen Algorithmen modulieren. Für den modernen Klang elektronischer Musik gibt es die Unison-Funktion, mit welcher man bis zu 16 Stimmen eines Oszillators erzeugen kann, die einen breiten Stereoeffekt ermöglichen. Es gibt zusätzlich noch einen Sampler, in welchen man eigene Samples laden und wie die anderen Oszillatoren mit Envelopes, LFOs, Filtern und Effekten bearbeiten kann. Alternativ kann man den Sampler auch als Whitenoise-Generator verwenden.
Die Envelopes und LFO’s erlauben komplexe Verläufe, die man selber mit der Maus einzeichnen kann. Damit lassen sich Sounds sehr detailliert einstellen. Diese Envelopes und LFO’s lassen sich auf fast jeden Parameter des Synthesizers legen. An dieser Stelle muss erwähnt werden, dass das Routing über Drag & Drop realisierbar ist, was diesen Synthesizer besonders einfach und schnell in der Bedienung macht. Es gibt auch eine klassische Routing-Matrix, mit welcher man noch ein wenig mehr Optionen hat, aber die grundlegenden Funktionen, lassen sich per Drag & Drop der LFO’s und Envelopes auf die Parameter bewerkstelligen. Möchte man komplexe Effekte, bestehend aus der Veränderung mehrerer Parameter, auf einen MIDI-Controller mappen, gibt es dafür mehrere Makro-Drehregler. Beispielsweise, kann man darauf einen Wavetable durchlaufen, diesen mit einem zweiten Oszillator modulieren, den Filter-Cutoff und zugleich den Sustain des Envelopes verändern.
Ich persönlich nutze oft auch die Random-Generatoren, die mehrere Modi wie z.B. Sample & Hold bieten und mit welchen man andere Parameter modulieren kann.
Die Filter reichen von simplen Hochpass- und Tiefpassfiltern bis hin zu Kammfiltern und speziellen Filtern, die unterschiedliche Vokale simulieren. Man kann zusätzlich zwischen “sauberen” digitalen Filtern und analogen Filtern, die Sättigungseffekte und andere Imperfektionen aufweisen, wählen.
Zur weiteren Klangverarbeitung bietet Vital eine Reihe an Effekten, wie Delay, Reverb, Distortion, Equalizer, Upward- und Downward-Kompressor (auch in Multiband-Ausführung) Chorus, Phaser, Flanger und einen zusätzlichen Filter. Auch diese lassen sich mithilfe der Envelopes und LFO’s modulieren.
Effects-Tab in Vital
Im Advanced-Tab kann man Vital noch hinsichtlich Klangqualität und Performance konfigurieren. Es gibt unter anderem Optionen für Oversampling, Qualität der Wavetables, Unison-Verhalten und Stimmung des Synthesizers.
Wieso ich Vital verwende?
Ideen tauchen oft als spontane Einfälle oder Geistesblitze auf, die ich schnell realisieren möchte und auch muss, bevor ich sie wieder vergesse. Da Vital schnelles und detailliertes Arbeiten erlaubt und ein breites Spektrum an Möglichkeiten abdeckt, ist dieser Synthesizer inzwischen in meine erste Wahl, wenn ich einen Klang synthetisch erzeugen möchte. Wenn ich Sounds hingegen durch Experimentieren und Limitieren meiner Möglichkeiten erzielen möchte, greife ich trotzdem noch gerne zu anderen Synthesizern (oft Emulationen analoger Geräte). Es ist dennoch erstaunlich, dass ein solcher Synthesizer, wie Vital, der teilweise kommerzielle Produkte hinsichtlich Features, Usability und Design überbietet, kostenlos zur Verfügung gestellt wird. Es gibt auch eine kostenpflichtige Plus- und Pro-Version, die vor allem mehr Wavetables und vorgefertigte Presets beinhalten, aber in der kostenlosen Version sind bereits alle Features enthalten.
Wer sich schon einmal die Signalketten bekannter Mixing oder Mastering-Ingenieure angesehen hat, dem wird schnell auffallen, dass häufig (oder fast überwiegend) analoge Kompressoren, die aus den 50er – 80er Jahren stammen, zu sehen dins. Viele moderne Geräte sind von diesen (aus Sicht der Tontechniker) “legendären” Kompressoren inspiriert und basieren auf den grundlegenden, technischen Prinzipien, die damals entwickelt wurden. Es gibt heutzutage auch viele virtuelle Emulationen dieser Geräte in Form von Plugins, die es in gewisser Form jedem ermöglichen die Kompressionscharakteristiken dieser Geräte zu nutzen ohne Unsummen (im vierstelligen Bereich!) für diese ausgeben zu müssen.
Grundsätzlich handelt es sich bei diesen Kompressoren um analoge Technik, die auf elektrotechnischen Schaltungen basiert. Von diesen Kompressoren gibt es vier Typen, die sich hinsichtlich ihrer Bauart und ihres Kompressionsprinzips unterscheiden. Dadurch unterscheidet sich natürlich auch die Klangcharakteristik der verschiedenen Typen.
VCA-Kompressoren (Voltage Controlled Amplifier)
VCA-Kompressoren sind die am meisten verbreiteten Arten von Kompressoren. Sie sind häufig in Mischpulten verbaut. Bei dieser Technik wird die Spannung mithilfe eines Transistors, der in einem integrierten Schaltkreis verbaut ist, direkt bearbeitet und erlaubt somit eine große Kontrolle der Kompressionsparameter Attack, Release, ThresholdRatio und in manchen Fällen Knee. Der Klang eines solchen Kompressors ist tendenziell neutral und somit vielseitig einsetzbar. Das ist bei Mischpulten, in welchen VCA-Kompressoren verbaut sind und die das Grundgerüst einer Mischung bilden, auch erwünscht.
Bekannte Geräte
SSL G Bus Kompressor, API 2500 Bus Kompressor, DBX 160A
SSL Bus Kompressor
API 2500 Bus Kompressor
FET-Kompressoren (Field Effect Transistor)
Bei FET-Kompressoren wird das Signal über eine spezielle Transistorschaltung komprimiert. FET-Kompressoren wurden als Alternative zu den langsamen Röhren- oder Opto-Kompressoren entwickelt und sind deshalb besonders, weil sie extrem schnelle Attack-Zeiten erreichen können. Im Gegensatz zu VCA-Kompressoren haben FET-Kompressoren einen starken, eigenen Klangcharakter, der das Signal in einer gewissen Form klanglich färbt. Durch eben die schnelle Reaktionsfähigkeit und der besonderen Färbung des Kompressors wird dieser oft bei Drums und Gitarren in Rock Songs genutzt, um einen aggressiveren Sound zu erzeugen.
Bekannte Geräte:
UREI/Universal Audio 1176, Drawmer 1978
Drei Versionen des 1176LN von Universal Audio
Opto-Kompressoren
Bei Opto- bzw optischen Kompressoren leuchtet im inneren des Gehäuses eine Lampe. Das Leuchten der Lampe ist je nach Pegel des Eingangssignals, unterschiedlich stark. Mithilfe eines Fototransistors wird die Lichtstärke registriert, was wiederum den Widerstand, der dem Audiosignal entgegengesetzt wird, reguliert. Daraus ergibt sich, dass ein starkes Signal stärker komprimiert wird als ein schwaches. Besonders ist bei Opto-Kompressoren, dass diese bauartbeding träge sind und somit längere Attack- und Release-Zeiten aufweisen. Zusätzlich dazu ist das Attack- und Release-Verhalten nicht linear und vom Pegel des Eingangssignals abhängig. Klanglich könnte man diese Art von Kompression durch diese Eigenheiten als “smooth” bezeichnen. Das macht diese Kompressoren hervorragand für die allgemeine Dynamikausbalancierung eines Signals Für die Kompression von Transienten eignet sich ein solcher Kompressor weniger.
Bekannte Geräte:
Teletronix LA-2A, Universal Audio LA-3A
Teletronix LA-2AUniversal Audio LA-3A
Variable-Mu-Kompressoren (Röhrenkompressoren)
Variable-Mu-Kompressoren waren die ersten Typen von Kompressoren in der Welt der Audiotechnik. Sie sind bauartbedingt ebenso träge, wie Opto-Kompressoren, und eignen sich somit zur allgemeinen Abrundung eines Signals. Wie der Name schon sagt, wird die Kompression mithilfe von Röhrentechnik realisiert. Klänge, die mit diesem Kompressor komprimiert werden, werden oft als wärmer und dicker wahrgenommen, weshalb sie häufig für die Veredelung von Klängen benutzt werden. Bekannte Geräte:
Die Nicht-linearität von Videospielen verlangt ein Soundsystem, das adaptiv ist und auf verschiedene Gegebenheiten reagieren kann. Zusätzlich wird bei verschiedenen Klängen eines Typs Variation erwartet, um ein glaubwürdigeres und nicht repetitives Hörerlebnis zu bieten. Die Middleware-Software Wwise bietet für eine Ansammlung an zusammenhängender Sounds sogenannte Container, die unterschiedliche Möglichkeiten bieten und an unterschiedliche Bedingungen geknüpft sind. Man kann Container zusätzlich ineinander verschachteln und quasi einen Container in einen anderen einfügen, womit man ein breites Spektrum an Verwendungsmöglichkeiten erhält[1]
Random Container
In diesem Container werden Soundfiles gesammelt, die in einer zufälligen Reihenfolge abgespielt werden. Diese Container finden Verwendung für Sounds wie Schritte, Schüsse usw. Random Container bieten außerdem weitere Funktionen, wie die Gewichtung von Sounds, also quasi welche Sounds priorisiert und somit häufiger abgespielt werden als andere. Man kann die Sounds noch zusätzlich hinsichtlich ihrer Tonhöhe randomisieren, um noch mehr Variation zu ermöglichen. Ein weiteres praktisches Feature ist das Verhalten der Reihenfolge, nachdem ein Sound abgespielt wurde (Play Type). Dabei kann man bestimmen, wie viele andere Sounds abgerufen werden müssen, damit das selbe Soundfile wieder abgespielt werden darf.
Random Container mit mehreren Soundfiles
Sequence Container
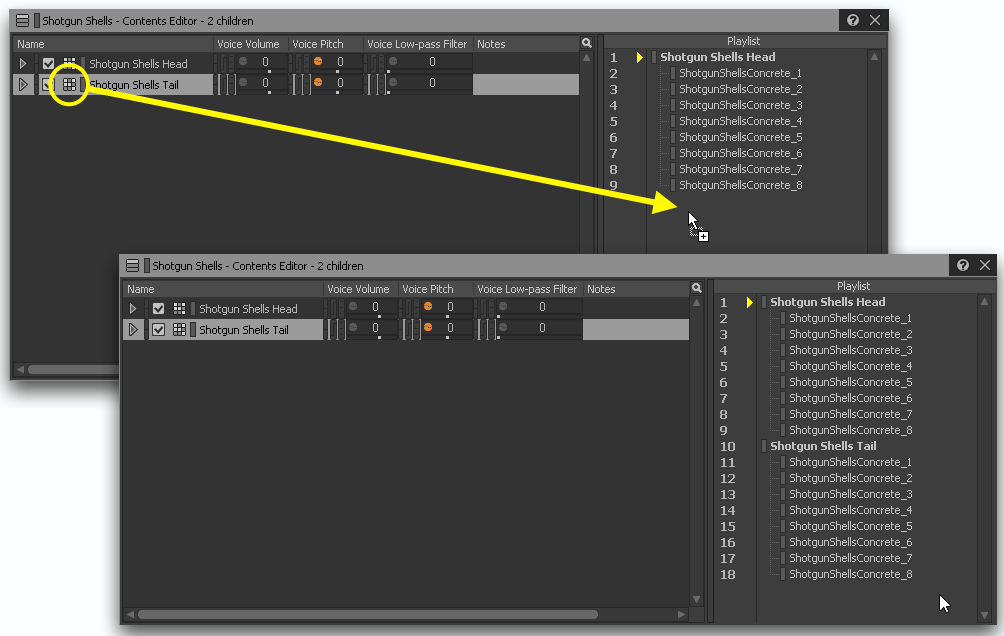
Hier werden Soundfiles in einer bestimmten Reihenfolge (Playlist) gespeichert und abgespielt. Das kann Sinn machen bei einem Dialog, der in einer bestimmten Reihenfolge abgespielt werden soll, oder auch bei komplexeren Sounds, die aus mehreren Segmenten zusammengesetzt werden, wie das Schießen einer Waffe. Dieses würde sich z.B. aus folgenden Sounds zusammensetzen: Betätigen des Abzugs -> Schussexplosion -> Abprallen der Patronenhülsen am Boden -> Nachladen [2]
Sequence Playlist gefüllt mit Soundfiles aus Random Containern
Switch Container
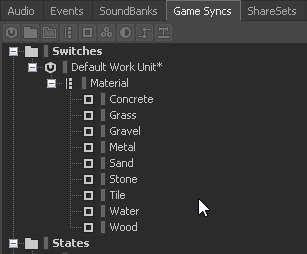
Ein Switch Container ist an Bedingungen geknüpft und ermöglicht das Abspielen passender Sounds an unterschiedliche Gegebenheiten. Hierzu werden sogenannte Switches verwendet, die im Spiel getriggert werden und an Wwise weitergeben, welcher Soundtyp abgespielt werden soll. Klassischerweise werden in Switch Containern z.B. Schritte in verschiedene Untergrundbeschaffenheiten eingeteilt. Switches stellen in diesem Fall das Material des Bodens dar [3]
Switch Container bei welchem Fußschritte in unterschiedliche Bodentypen eingeteilt werdenSwitches mit verschiedenen Materialen
Blend Container
Bei diesem Containertypen können Sounds graduell von einem Sound zum anderen mittels eines Crossfades übergeblendet werden. Das macht Sinn für Klänge, die unterschiedliche Intensitätsstufen benötigen, wie z.B. unterschiedliche Windstärken, Motorengeräusche, die abhängig sind von der Drehzahl oder die Arrangementfülle eines Musikstücks. Dazu wird mittels RTPCs (Real Time Parameter Control), also Parametern, die im Spiel graduell getriggert werden, bestimmt, welche jeweilige Intensitätsstufe abgespielt wird. Eine Intensitätsstufe wird jeweils durch ein Soundfile repräsentiert.
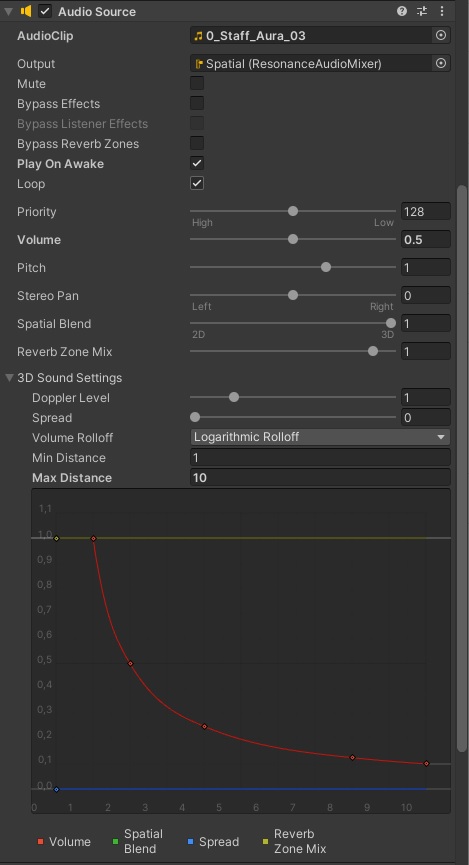
In meiner praktischen Studienarbeit arbeite ich aktuell an einem Sound Design für ein 3D Adventure Game. In diesem gibt es Elemente, die in einer Endlosschleife geloopt werden sollen. Klassisch zählen hierzu Atmosgeräusche, fließendes Wasser, Wind und auch der Soundtrack. In meinem Fallen handelt es sich um einen Zauber-/Lichteffekt, der um einen aufsammelbaren Stab herumschwirrt.
Zauberstab-Lichteffekte sollen in Dauerschleife klingen
Die meisten Game Engines bieten Funktionen, mit welchen Soundfiles geloopt werden können.
Loop-Funktion in Unity
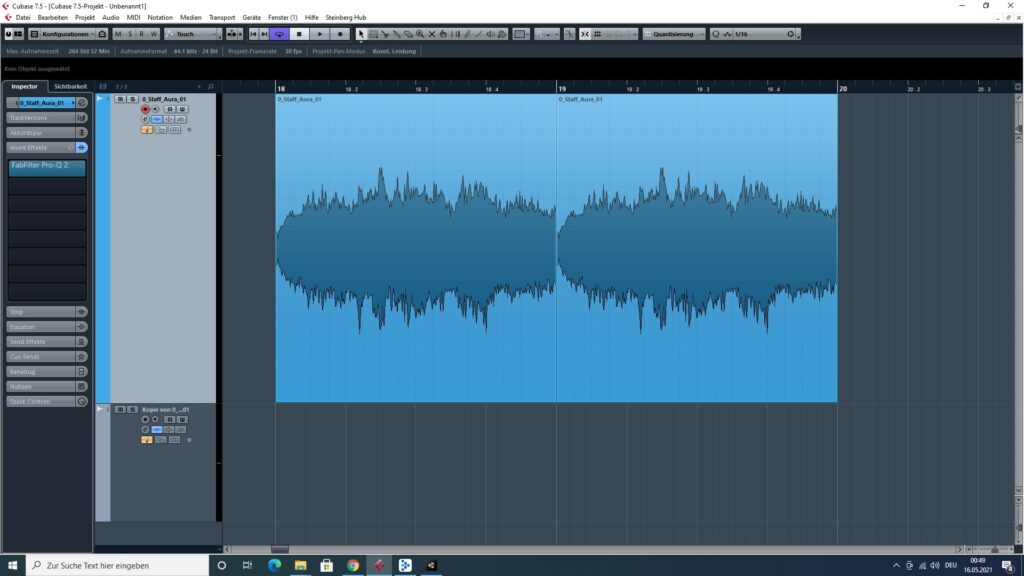
Wenn die Loop-Funktion nun bei einem gewöhnlichen Soundfile aktiviert wird, fällt jedoch auf, dass ein Knacksen zu hören ist, sobald die Datei wieder von vorne abgespielt wird. Das liegt daran, dass die Wellenform am Ende der Aufnahme sich von der Wellenform am Anfang unterscheidet.
Simulierter Loop ohne ÜbergangLoop ohne Übergang
Audio-Middlewares, wie Wwise, ermöglichen die interne Umsetzung von Übergängen, womit artefaktfreies Looping möglich ist.
Transition-Optionen in Wwise
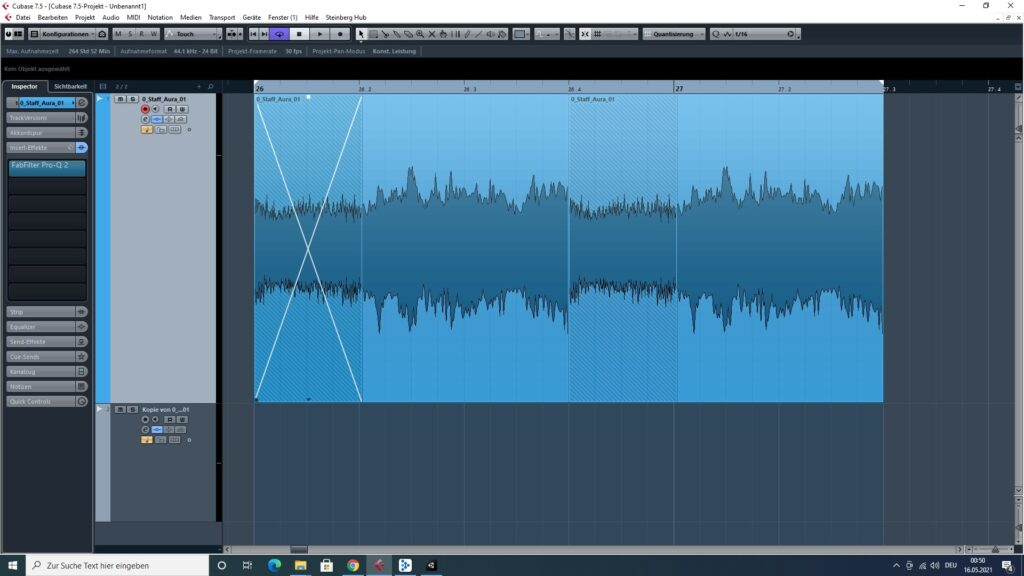
Man kann aber auch Soundfiles bereits in der DAW aufbereiten, damit diese auch ohne Middleware-Programmen und somit universell loop-tauglich sind. Man schneidet dafür das Ende des Soundfiles aus und fügt den ausgeschnittenen Teil der Aufnahme am Anfang des Soundfiles ein [1]. Anschließend wird ein Crossfade zwischen den beiden Audio-Events gesetzt. Damit erklingt nun kein Knacksen mehr, wenn die Datei beim Loop wieder von Anfang abgespielt wird und er Übergang verläuft flüssig.
Simulierter Loop mit ÜbergangLoop mit Crossfade
Alternativ kann auch das Audio-Event, welches am Ende ausgeschnitten wird, auf eine zweite Spur gelegt werden, womit man den Fade-In und Fade-Out unabhängig voneinander bestimmen kann. Die Länge der Fades kann je nach Bedarf angepasst werden und ist vom Material abhängig.
Vor kurzem bekam ich eine eine Hausaufgabe, bei welcher ich eine Actionfilmszene aus “Mission Impossible 2” vertonen musste. Dabei durften Sounds nur mithilfe des Mundes und der Stimme erzeugt und nur mit klassischen Sound-Design-Tools, wie Time-Stretching, Pitch-Shifting, Layering, Cutting und Equalizing bearbeitet werden. In dem Ausschnitt, die ich zu vertonen hatte, kam eine Szene vor, bei welcher ein Auto explodiert. Für Explosionen werden im Sound Design häufig sogenannte Impact Sounds verwendet, die einen stark perkussiven Klangcharakter haben und sich durch ausgeprägte Transienten und lange Release-Zeiten definieren. Mit der Stimme oder dem Mund ist es allerdings schwierig einen Sound zu generieren, der vor allem im Tieftonbereich explosiv wirkt und die Kinowände zum Schwingen bringt.
Für einen tiefen Impact-Sound, wie ich ihn gerne für die Explosion hätte, würde ich generell eine Kickdrum verwenden und sie mit einem langen Hall-Reverb versehen. Zur Erstellung der Kickdrum aus meiner Stimme orientiere ich mich an der Klangsynthese einer elektronischen Kick. Diese basiert auf einem schnellen Sinussweep vom hohen Spektrumsbereich in den tiefen.
Als Ausgangssignal muss es sich nicht zwangsweise um einen perfekten Sinuston handeln. Mit der Stimme ist das auch nicht möglich, deshalb singe ich zunächst einen “U”-Vokal ins Mikrofon.
Die rohe Aufnahme des U-Vokals
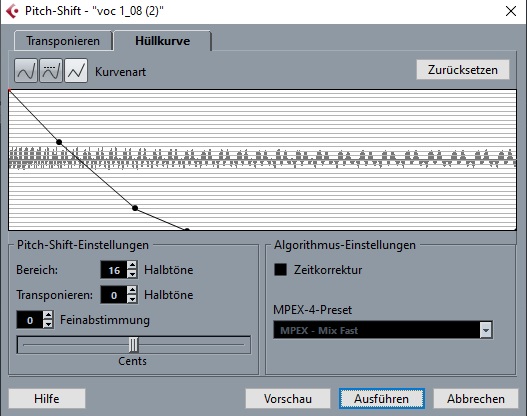
Nun beschneide ich die Aufnahme so, dass sie mitten im U-Vokal anfängt und auch endet und wende anschließend einen Pitch-Shifting-Effekt an, der mithilfe eines Envelopes von einem hohen zu einem tiefen Ton moduliert wird.
Cubase’ eigener Pitch-Shifting-EffektU-Vokal nach dem ersten Pitch-Shifting-Durchlauf
Da Cubase’ eigener Pitch-Shifter nur im Bereich von 16 Halbtönen modulieren kann, wende ich den Pitch-Shifter noch ein zweites Mal an.
U-Vokal nach dem zweiten Pitch-Shifting-Durchlauf
Nun habe ich einen Klang, der die wichtigsten Frequenzbereiche abdeckt und auch die perkussive Charakteristik einer Kickdrum abbildet. Um daraus nun einen Impact-Sound zu generieren, verfeinere ich den Sound noch mithilfe eines Equalizers und Multibandkompressors und lege einen Reverb darauf. Dabei muss der Reverb einen langen Decay haben und besonders im Tieftonbereich lange nachklingen. Ich habe hierfür gute Erfahrungen mit Convolution-Reverbs, also Impulsantworten tatsächlicher Räume, machen können.
Finale Effekte für den Impact-SoundImpact-Sound
Als Alternative dazu kann man auch die hohen Frequenzen mittels Tiefpass-Filter entfernen und erhält damit einen tiefen Impact-Sound, den man beispielsweise oft in Trailern hört.
Tiefer Impact-Sound
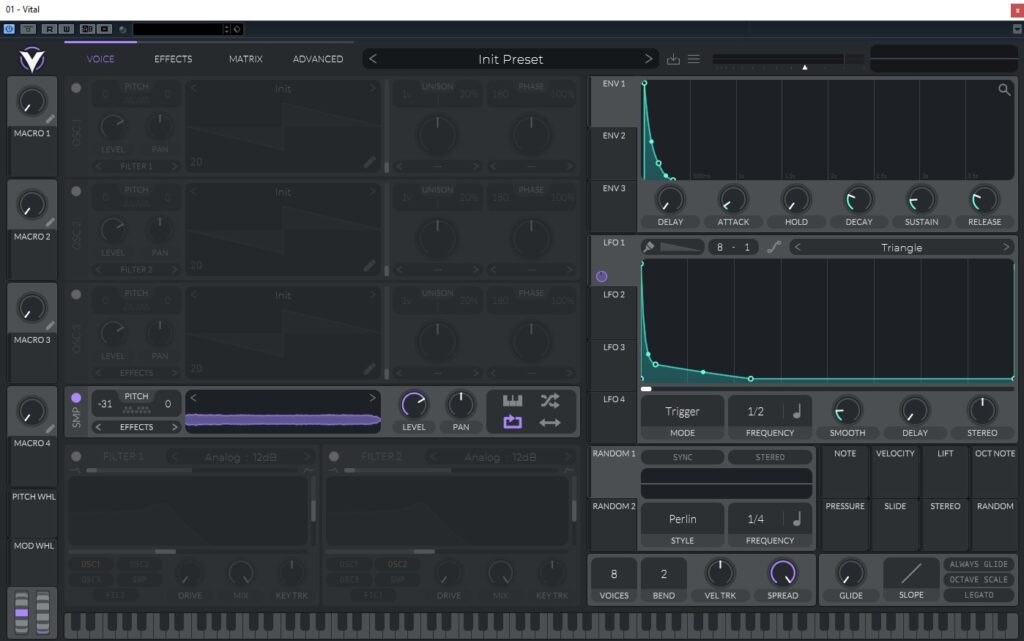
Ich habe noch eine zweite Fassung erstellt, bei welcher ich statt des Cubase Pitch-Shifters einen Sampler verwende, mit welchem der Pitch-Shift nicht auf 16 Halbtöne limitiert ist. Dazu verwende ich den frei-erhältlichen Synthesizer Vital, der auch Samples abspielen kann [1]. Ich senke den Pitch generell um 31 Halbtöne ab und moduliere zusätzlich mithilfe eines LFO’s die Tonhöhe von oben nach unten. Den Volume-Envelope stelle ich so ein, dass das die Transiente besonders ausgeprägt ist und schnell leiser wird, allerdings genug Bass-Anteil vorhanden bleibt. Nun habe ich einen Kick-Sound, der glaubwürdiger klingt als nach Cubase’ eigenen Pitch-Shifting. Tatsächlich macht das aber für den Impact-Sound nur einen kleinen Unterschied.
Kick-Sound mit Vitals SamplerU-Vokal nach Vitals Pitch-Shifting
Nun lege ich noch einen Reverb-Effekt darauf und erhalte einen Impact-Sound.
In den letzten Jahren sind verschiedene AI-basierte Produkte in der Welt der Tonproduktion angekommen. Dabei erfreuen sich Online-Mastering-Dienste, wie LANDR oder eMastered einer großen Popularität [1, 2]. Diese Dienste erlauben ein schnelles Mastering von Musikstücken per Drag & Drop auf Basis von AI-Technologien. Der Dienst Aria bietet sogar ein automatisches Mastering mit der Einbindung analoger Hardwareprozessoren an, die von einem Roboterarm gesteuert werden [3]. Wer mehr Kontrolle über das Mastering haben möchte, kann auch mit Izotopes Mastering-Suite Ozone sein Musikstück analysieren sich eine AI-generierte Bearbeitung mittels verschiedener Module vorschlagen lassen, in die man jedoch auch noch selbst eingreifen kann [4]. Gullfoss von Soundtheory arbeitet ebenfalls mit künstlicher Intelligenz und dient als Werkzeug, das Maskierungseffekte erkennt und diese, so gut wie möglich, beseitigt [5]. Dabei werden zu dominante Frequenzanteile abgesenkt und Frequenzanteile, die eigentlich maskiert werden würden, mittels eines dynamischen Equalizers angehoben. Das Resultat ist im Optimalfall ein detailreicheres Signal.
Auch hat AI den Weg in die Komposition gefunden und schon teilweise erstaunliche Ergebnisse erzielt. Vor kurzem wurde ein Projekt namens „Lost Tapes of the 27 Club“ veröffentlich, bei welchem Musikstücke von Künstlern analysiert wurden, die zum „Club 27“ gehören – also die im Alter von 27 Jahren verstorben sind – und auf dieser Basis Kompositionen im selben Stil geschaffen wurden.
Aus der Beschreibung des Projekts kann man allerdings entnehmen, dass nur die musikalischen Elemente von künstlicher Intelligenz erstellt wurden. Ein Toningenieur hat diese Elemente letzten Endes noch arrangiert und zu vollständigen Songs zusammengefügt. Hierbei wäre es interessant zu wissen, welches Material die AI generiert hat und wie viel kreative Arbeit der Toningenieur übernommen hat. [6]
Jetzt stellt sich die allgemeine Frage: Ist der Beruf des Toningenieurs bzw. des Kunstschaffenden im Audiobereich durch künstliche Intelligenz bedroht? Das lässt sich nicht so einfach beantworten. Künstliche Intelligenz wird früher oder später technisch einwandfreie Ergebnisse liefern können, jedoch ist die Tonproduktion auch vor allem ein kreativer Prozess, bei welchem intuitive Entscheidungen auf Basis von Geschmack und Emotionen getroffen werden. Diese sind viel tiefer in der Psyche des Menschen verankert und bilden sich aus mehreren Faktoren als nur aus der Auswertung ähnlicher Musikstücke desselben Genres [7]. Künstliche Intelligenz betrachtet Musik und Menschen nicht ganzheitlich und kennt somit auch keine Emotionen, die mit Musik verbunden sind. Davon ist künstliche Intelligenz auch noch weit entfernt.
Ein weiterer Punkt, der durch künstliche Intelligenz nicht abgedeckt ist, ist der Austausch und das Feedback zwischen den verschiedenen Schritten einer Audioproduktion. Ein AI-basiertes System lässt quasi blind einen Algorithmus über ein Musikstück laufen, während z.B. ein Mastering-Ingenieur sich das Material anhört und Feedback an den Mixing-Ingenieur oder Produzenten geben kann, damit die Probleme in einem der vorherigen Schritte behoben werden können, wo die Möglichkeiten zur Fehlerbehebung größer sind und dadurch auch das klangliche Resultat in der Regel besser ist. Diese beratende Funktion fehlt bei AI-Algorithmen komplett, spielt aber eine wesentliche Rolle bei einer Audioproduktion.
Zu einem gewissen Grad umgehen viele Online-Mastering-Nutzer dieses Problem, indem sie ein AI-generiertes Mastering lediglich nur als Referenz nutzen, um auf dieser Basis Probleme in der Mischung oder einem der vorherigen Produktionsschritte zu beseitigen [8].
Aktuell ist künstliche Intelligenz in der Audioproduktion noch kein gleichwertiger Ersatz für einen erfahrenen Toningenieur, Produzenten usw. Allerdings haben AI-Technologien eine Daseinsberechtigung und können auch einen Mehrwert bieten. Ob sie jemals eine Konkurrenz für den Menschen darstellen werden, kann man nicht genau sagen. Aktuell ist der technische Stand noch nicht weit genug, um kreative Schaffensprozesse auf demselben Niveau, wie dem eines Menschens, nachzuahmen.
Im letzten Blogeintrag habe ich einen kleinen Einblick gewährt in die Geschichte des sogenannten Loudness Wars. Dieser basiert aus technischer Sicht auf der dynamischen Einschränkung von Musikstücken mithilfe extremer Kompression, womit hohe Lautsheitswerte erzielt werden können. Klassischerweise werden für diese Aufgabe Kompressoren und vor allem Limiter verwendet. Es gibt allerdings auch noch eine weitere Möglichkeit, um den Dynamikumfang eines Musikstücks einzuschränken – das Clipping. Bei jedem Toningenieur läuten jetzt die Alarmglocken, weil normalerweise gilt, jegliche Form von Clipping im Signalweg zu vermeiden, indem der Pegel in der digitalen Domäne unter der 0 dBFS-Grenze gehalten wird [1]. Das ist auch korrekt und sollte in der Regel so eingehalten werden. Allerdings werden bei Musikrichtungen, wie Metal, Hip-Hop und diversen elektronischen Genres, die für den Club produziert werden, extreme Lautheitswerte erwartet, die klanglich transparenter durch den Einsatz von bewusstem Clipping statt Limiting erzielt werden. Während Limiter Pegelspitzen absenken, indem sie, idealerweise vorausschauend, das Signal analysieren und dann mit den vom Ingenieur eingestellten Attack und Release-Zeiten arbeiten, werden beim Clipping ganz einfach Pegelspitzen ohne Attack- und Release-Wartezeiten abgeschnitten. Dadurch entstehen innerhalb des Zeitraums, in welchem der Pegel die 0 dBFS-Grenze übersteigt Verzerrungen. [2]
Während beim starken Limiting oft Transienten ihre Präsenz verlieren oder ungewolltes Pumpen (anheben und absenken des Gesamtpegels auf Basis der Attack- und Release-Zeiten) entsteht, klingt Clipping oft natürlicher bzw. transparenter und kann sogar Transienten mithilfe der entstehenden Verzerrungen hervorheben.
Bei einer Untersuchung wurde die Hörbarkeit von digitalen Clipping-Verzerrungen ermittelt und man ist zu dem Ergebnis gekommen, dass die Hörbarkeit stark vom Audiomaterial und auch individuell vom Hörer abhängig ist. Daraus kann man schließen, dass für die Anwendung von Clipping ein geschultes Ohr voraussetzend ist und auch das Ausgangsmaterial ausschlaggebend ist, ob und wie schnell Artefakte hörbar werden. [3]
In den 2000er-Jahren kamen für das Clipping hochwertige A/D-Wandler zum Einsatz. Diese wurden mit einem Signal angesteuert, bei welchem die analogen Pegelspitzen bei der Wandlung ins digitale theoretisch 0 dbFS überschreiten würden und deshalb an dieser Stelle geclipped wurden. Die daraus resultierenden Verzerrungen waren entweder kaum hörbar, was auch zu keinen klanglichen Einbußen der Audioqualität geführt hat, oder haben im besten Fall den Klang sogar aufgewertet. [4, 5, 6, 7]
Auf virtueller Ebene gibt es für das Clipping spezielle Plugins, die mit Oversampling-Funktionen ausgestattet sind, um Aliasing-Artefakte so gering wie möglich zu halten. Außerdem bieten viele Clipper verschiedene Steigungskurven an, die aus einem Hard-Clipper einen Soft-Clipper machen, bei welchem leichte Verzerrungungen bereits unterhalb des eingestellten Thresholds auftreten und das Ausmaß der Verzerrung graduell bis zum Threshold ansteigt. [8, 9, 10, 11]
Wie man sieht, sollte Clipping per se nicht als „Fehler“ abgestempelt, sondern vielmehr als Werkzeug des Toningenieurs gesehen werden, das eine Alternative zum klassischen Limiting darstellt. Wenn Clipping bewusst und mit Vorsicht in einer Produktion genutzt wird, kann es sogar in gewissen Musikgenres als stilistisches Element dienen, welches den Klang sogar aufwerten kann. Letzten Endes sollte das Ohr entscheiden, ob der Einsatz eines Clippers sinnvoll ist und besser klingt als ein Limiter.