It is a treatment based on music as therapy, which emphasizes some specific musical elements (such as rhythm, melody, dynamics, tempo) in the construction of the therapy, to treat people with neurological disorders.
It is based on the neuroscientific research of perception and music production. Furthermore, it also examines how the brain responds to music and affects neuroplasticity to help the brain recover from injury in the areas of movement, language and cognition.
Music and rhythm affect multiple areas of the human brain at a subconscious level, this means that rhythm can be used to build connections in the brain, thereby improving its functions. This leads to a more productive and functional life.
There is however a difference between Music Therapy and NMT.
Music Therapy seeks more to treat aspects of patient need such as emotional, physical and mental.
NMT focuses on the physical effect of music and rhythms on the brain and its connections through NMT intervention, which are specific research-based techniques.
Here is an example of an approach to neurological music therapy from the Spaulding rehabilitation network:
Sensorimotor: Upper Extremity, Lower Extremity, Gait Training
Cognition: Attention, Memory, Initiation, Executive Function, Neglect training
Treatment areas include:
Traumatic Brain Injury
Acquired Brain Injury
Stroke
Huntington’s Disease
Parkinson’s Disease
Cerebral Palsy
Alzheimer’s Disease
Autism
The therapy session varies according to the goal of the patients.
When working on speech, they may practice using their voice while singing along with rhythmic guitar playing or preparing their vocal muscles by playing wind instruments.
When working on attention, they have a musical instrument to play while concentrating on sitting in their chair.
When working on walking or other physical movement, they may move around playing drums in the walking track or in the therapy room.
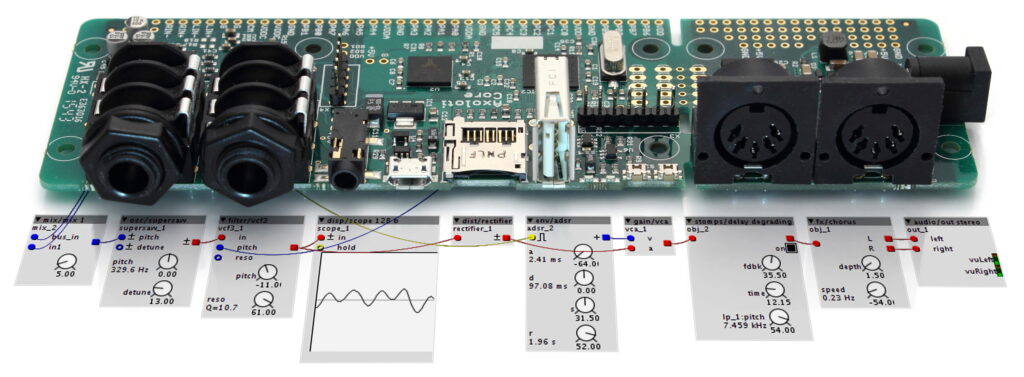
Das Axoloti Board eignet sich hervorragend, um Prototypen von anzufertigen. Es ist ein Board mit vielen I/O Pins, stereo Audio in- und Output, A/D und D/A Wandlern. Das Board ist mit dem Axoloti Patcher programmierbar. Eine Software, mit der man komplexe Sound Algorithmen und Interaktionen auf einfache Art und Weise generieren kann, die man nach dem Erstellen einfach auf den Axoloty lädt und danach im Standalone Betrieb verwenden kann. Ein Nachteil ist, dass die Software seit Mac OS Catalina nicht mehr unterstützt wird, ansonsten hätte ich damit gerne einen ersten Prototypen programmiert.
Axoloti Patcher
Der Axoloti Patcher funktioniert ähnlich wie MaxMSP oder Pure Data. Man hat verschiedene Objekte zur Verfügung, wie beispielsweise Input/output, LFO´s, Oscillators etc. Mit diesen Objekten kann man auf einer grafischen Oberfläche seine Signalkette programmieren.
Leider gibt es unter Mac OS Catalina und Big Sur Kompatibilitätsprobleme mit der Software.
Videospiele sind ein interaktive Medien, die einen interaktiven bzw. adaptiven Soundtrack erfordern. Tatsächlich muss aber zwischen interaktiver und adaptiver Musik unterschieden werden. Diese werden zwar oft in einen Topf geworfen, aber sie sollten dennoch unterschieden werden, weil sie genau genommen zwei unterschiedliche Dinge meinen. Der Komponist Michael Sweet spricht von interaktiver Musik, wenn der Spieler mit spielerischen Handlungen direkt die Musik beeinflussen kann, wie beispielsweise in Spielen wie Guitar Hero [1]. Adaptive Musik hingegen umfasst Musik, bei welchen der Spieler eine indirekte Kontrolle über die Musik hat. Diese reagiert, statt auf Tastenbefehle und anderen Eingaben des Spielers, auf Faktoren der Spielwelt wie Tageszeit, Wetter, Grad der Bedrohung, Spannungsintensität usw. David Vink schreibt, dass Musik adaptiv ist, wenn sie sich an Umweltbedingungen im Spiel anpasst [2]. Interaktive Musik hingegen wird durch den Spieler direkt ausgelöst. In diesem Artikel beziehe ich mich auf Methoden der adaptiven Musikgestaltung.
Adaptive Soundtracks werden, wenn sie mit Filmsoundtracks verglichen werden, auch als nicht-lineare Soundtracks bezeichnet. Filmmusik hingegen ist linear, da die Abfolge auf einer linearen Zeitachse stattfindet. In Videospielen ist die Abfolge der Handlung abhängig davon, wie und wann ein Spieler Aktionen durchführt. Dementsprechend muss der Sound auch die Fähigkeit besitzen sich an die Aktionen des Spielers anzupassen. [3, 4]
Wieso soll ein Soundtrack adaptiv sein?
Adaptive Soundtracks sind also Musikstücke, die auf verschiedene Umstände im Spiel reagieren. Nun stellt sich die Frage, wieso sollte ein Soundtrack überhaupt adaptiv sein? David Vink spricht davon, dass adaptiver Sound eine größere Wirkung auf den Spieler hat und gleichzeitig als Kommunikationsmittel dient. Beispielsweise, kann der Wechsel zu einem sehr rhythmischen Stück symbolisieren, dass der Spieler sich in der Nähe eines Gegner befindet. Das Musikstück trägt in dem Fall die Information der Bedrohung durch einen Gegner.
Wieso ein adaptiver Soundtrack eine größere Wirkung auf den Spieler hat, hat mehrere Gründe:
In emotionalen Momenten ist die menschliche Wahrnehmung empfindlicher auf die Umgebung, zu welcher auch die auditive Ebene gehört. Wenn z.B. also im Spiel gerade ein intensivere Herausforderung vom Spieler gemeistert wurde, erwartet der Spieler einen Moment der Erleichterung. Da der Spieler in solchen Momenten besonders auf die klangliche und visuelle Umgebung achtet, muss die Musik auch als passend empfunden werden.
Als weiteren Grund nennt er die willentliche Aussetzung der Ungläubigkeit. Diese ist notwendig um fiktive Videospiele als glaubwürdig und logisch zu sehen bzw. zu akzeptieren. Ein Soundtrack, der für die Umstände im Spiel nicht passend wäre, würde die willentliche Aussetzung der Ungläubigkeit hindern und das Spiel unglaubwürdig wirken lassen. Ein Soundtrack der hingegen adaptiv ist und zu jeder Situation als passend empfunden wird, erhöht stattdessen die Glaubwürdigkeit der Spiels und wird als Teil der Spielwelt angenommen. [2]
Was als passend und glaubwürdig empfunden wird, ist abhängig von der Erwartungshaltung des Spielers, die sich wiederum aus subjektiven Präferenzen bildet [5]. Dazu kommt auch noch, dass der Grad der Immersion des Spiels eine Rolle spielt. Immersion bezeichnet in dem Fall die Involviertheit des Spielers in ein Spiel und die Ausblendung der realen Welt. Dieses Thema werde ich allerdings erst in einem meiner nächsten Blogposts behandeln, da es den Rahmen dieses Artikels sprengen würde.
Methoden zur Umsetzung adaptiver Soundtracks
In den letzten 20 Jahren haben sich einige Standardmethoden zur adaptiven Soundtrack-Gestaltung etabliert. Diese haben unterschiedliche Vor- und Nachteile und werden für verschiedene Funktionen genutzt. Die Umsetzung dieser Methoden geschieht in der Regel über Middleware-Software, wie FMOD oder Wwise. In vereinfachter Form kann sie aber auch direkt in der Spiel-Engine implementiert werden.
Die zwei Grundprinzipien, auf welchen adaptive Soundtracks basieren, heißen Horizontal Resequencing und Vertical Remixing. Zur Beschreibung dieser Methoden, beziehe ich mich auf die Ausführungen Micheal Sweets in seinem Buch “Writing Interactive Music for Video Games: A Composer’s Guide” und auf die Erläuterungen aus dem offiziellen Wwise-Zertifizierungskurs von Audiokinect. [6, 7, 8]
Horizontal Resequencing
Horizontal Resequencing beschreibt eine Methode, bei welchem die Musik von einer Sektion entweder zu einer anderen Sektion oder zurück zum Anfang (Looping) springt. Es ist auch möglich, dass das aktuell laufende Musikstück durch ein komplett anderes Musikstück ersetzt wird. Der Begriff „Horizontal“ beschreibt in dieser Methode den zeitlichen Ablauf einer Komposition, der traditionellerweise auf der horizontalen Achse notiert wird. Für diese Methode gibt es mehrere Möglichkeiten, wie Übergänge realisiert werden. Diese Möglichkeiten umfassen Crossfades, Transitional Scores und Branching Scores.
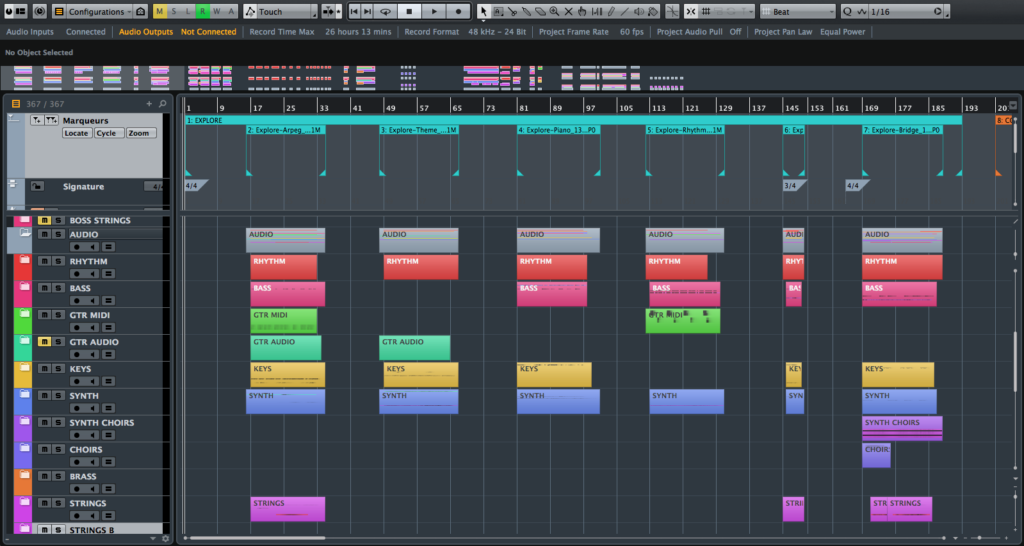
Abbildung 1: Cubase-Projekt mit mehreren Sektionen, die voneinander getrennt sind
Crossfading
Bei dieser Art von Übergängen wird der Pegel des aktuell laufenden Musikstücks verringert, während simultan der Pegel des nächsten Musikstücks erhöht wird. Vorteil hierbei ist, dass ein Crossfade jederzeit realisierbar ist und somit schnell auf das Spielgeschehen reagieren kann. Klanglich kann jedoch ein Crossfade in vielen Fällen nicht zufriedenstellend klingen, weil es an das Umschalten von Radiosendern erinnert und nicht sehr musikalisch wirkt.
Um den entgegenzuwirken können die Musikstücke im Tempo aneinander angepasst werden, sodass die Übergänge in sich stimmiger klingen. Bei dem Spiel Witcher 3 haben die Musikstücke, die potentiell oft abwechselnd hintereinander abgespielt werden, wie die Erkundungs- und die Kampfmusik, das selbe Tempo und die selbe Taktart. Zusätzlich ist der überwiegende Teil des Soundtracks in der Tonart D-Moll, was die Übergänge leichter gestaltet.
Transitional Scores
Dieser Übergang verbindet Sektionen oder Musikstücke mithilfe eines musikalischen Elements oder eines Soundeffekts. Bei einer guten Umsetzung eines solchen Übergangs können Musikstücke mit verschiedenen Tempi, Taktarten und Tonarten miteinander verbunden werden und dabei in einen musikalischen Kontext gesetzt werden. Für solche Übergänge eignen sich beispielsweise Crescendi, Glissandi oder auch Soundeffekte wie umgekehrt abgespielte Crashbecken, die aus der elektronischen Tanzmusik oder auch der Popmusik bekannt sind.
Branching Scores
Bei dieser Übergangsmethode gibt es keinen eigentlichen Übergang. Das laufende Musikstück wird vom nächsten Stück ohne einem Crossfade abrupt abgelöst. Damit der Übergang als fließend und passend wahrgenommen wird, geschieht der Wechsel des Musikstücks immer am Ende einer musikalischen Phrase. Bei längeren Phrasen kann das Problem auftreten, dass im Spiel bereits eine neue Handlung einsetzt, während noch die Musik der letzten Handlung läuft, weil die Phrase zu Ende gespielt werden muss. Für diese Methode eignen sich stattdessen kurze musikalische Phrasen, da sie schneller auf das Geschehen reagieren können. Diese Methode kann außerdem genutzt werden, um ein Musikstück in mehrere kleine Segmente aufzuteilen, die in zufälliger Reihenfolge abgespielt werden. Das umgeht die Monotonie, die entsteht, wenn ein Musikstück ständig wiederholt wird und sorgt für eine klangliche Abwechslung.
Vertical Remixing
Vertical Remixing basiert auf dem Prinzip des Layerings von Musikstücken. Dabei werden verschiedene Instrumentengruppen in verschiedene Layer aufgeteilt, die je nach Bedarf (Spannungsgrad, Bedrohungsgrad usw.) hinzugefügt werden können. Die Bezeichnung „Vertical“ ist damit begründet, dass Instrumentengruppen in einer Partitur oder in einer Digital Audio Workstation vertikal angeordnet werden. Im Gegensatz zum Horizontal Resequencing arbeitet Vertical Remixing nur mit einem Musikstück, das eine lineare Zeitachse hat. Das hat zur Folge, dass Tonart, Tempo, Taktart und Abfolge vorherbestimmt sind und bei jeder Wiederholung unverändert bleiben. Das sorgt einerseits für eine Kontinuität des Soundtracks, mit welcher die Immersion nicht gestört wird, gleichzeitig ist die Bandbreite an kompositorischen Möglichkeiten hinsichtlich der harmonischen und rhythmischen Abwechslung überschaubar. Grundsätzlich gibt es zwei Möglichkeiten, wie Layer implementiert werden: additiv und individuell kontrolliert.
Additive Layer
Beim additiven Layering wird durchgehend ein Grund-Layer abgespielt und, je nach Bedarf, werden weitere Layer hinzugefügt, sobald Trigger ausgelöst werden. Trigger sind bedingt durch Zustände der Charaktere oder der Spielwelt. Sie beschreiben häufig die Position und die Umgebung, in welcher sich der Charakter des Spielers befindet. Oft gibt es die sogenannte Exploration Music, die das Grund-Layer bildet und die musikalische Untermalung zur Erkundung der Spielwelt darstellt. Je nach Bedarf kommen weitere Layer hinzu. Im Spiel Fallout: New Vegas symbolisiert z.B. die Intensität, die durch das addieren von Layern erzeugt wird, die Nähe zur nächsten Stadt. Je näher der Spieler am Stadtzentrum ist, desto mehr Layer kommen hinzu. In Mass Effect 2 aktiviert das Beginnen eines Kampfes ein Layer bestehend aus Percussion-Instrumenten.
Individuell kontrollierte Layer
Bei dieser Art ist jeder Layer alleinstehend und hat jeweils einen eigenen Trigger. Damit lassen sich verschiedene Situationen im Spiel musikalisch abbilden, die nicht, wie beim additiven Layering aufeinander aufbauen, sondern sich auch gegenseitig ablösen können. Außerdem gibt es auch keinen Grund-Layer, der konstant abgespielt wird. Einige mögliche Layer sehen wie folgt aus: Es gibt einen Layer, der signalisiert, dass der Charakter nur noch wenig Lebenspunkte hat, einen Layer der aktiviert wird, wenn der Spieler geht, und einen Layer, der zu hören ist, wenn der Spieler schwimmt. Dieser Layer wechselt sich mit dem vorherigen ab und kann nicht simultan erklingen, da die beiden Layer zwei verschiedene Zustände darstellen. Allgemein lassen sich mit individuell kontrollierbaren Layern komplexere adaptive Systeme gestalten, die auf verschiedene Zustände reagieren können. Oft wird eine Kombination aus additiven und individuell kontrollierten Layer-Methoden genutzt.
In der Regel werden die Layer mit Lautstärkeautomationen bzw. Fades klanglich ein- und ausgeblendet. Wie lang die Fades dauern, entscheidet das technische Audio-Team oder die Entwickler selbst. Lange Fades fallen weniger auf als kurze oder abrupte Fades. Die Länge variiert nach Michael Sweets Erfahrung zwischen 3000 und 5000 Millisekunden und ist abhängig vom Stil und Tempo der Musik.
Vor- und Nachteile
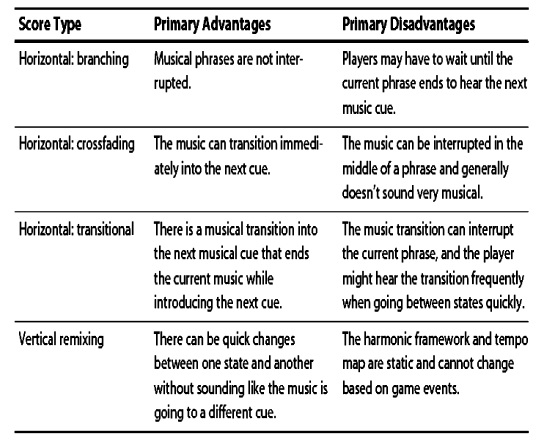
Die verschiedenen Arten von adaptiven Techniken in der Soundtrack-Gestaltung haben jeweils eigene Vor- und Nachteile. Meistens wird eine Kombination aus mehreren Methoden benutzt, die spezielle Einsatzgebiete haben, in welchen die Methoden von ihren Stärken profitieren. In der folgenden Tabelle von Michael Sweet werden zusammenfassend alle Vor- und Nachteile aufgelistet.
Abbildung 2: Übersicht der Vor- und Nachteile der verschiedenen Methoden
Zusammenfassung
Es gibt also verschiedene Möglichkeiten, die zur adaptiven Soundtrack-Gestaltung eingesetzt werden können. Welche Methoden verwendet werden, ist abhängig von der benötigten Funktion bzw. dem zu erzielenden Effekt. Für einen eindrucksvollen adaptiven Soundtrack wird eine gute Kommunikation zwischen dem Komponisten und dem Audio-Team bzw. den Entwicklern des Spiels erfordert. Nur, wenn der Komponist die Vision des Spiels und die Idee hinter den vorgesehenen Anwendungszwecken versteht, kann dieser gezielt einen Soundtrack erstellen, der die verschiedenen Situationen im Spiel und der Spielwelt abdeckt.
In 2018 one event shook the electronic music scene- Avicii had committed suicide, shortly after his close friends reported how happy and inspired he seemed. He retired from playing shows and instead of getting better, it looks like he got worse. The event was quite a shock, but it lead to numerous other electronic musicians to take a break from music and focus on their mental health. Last year Eric Morillo (49) and i_o (30, one of my personal favourites) both committed suicide, along with countless others- the list is too long. What is behind these events? The trend is worrying and uncovers a dangerous truth hidden behind the DJ desks…
Mental health has always been a big issue in the music scene, especially after the rise of popularity in drugs. This is especially prevalent in the electronic/dance scene. The deadliest part of the whole story is the lack of sleep. DJs can sometimes play daily shows up to months at a time, leading to dangerous lack of sleep. They take drugs and drink alcohol in order to keep u with the crowd and also stop themselves from crashing. This is a vicious cycle that leads to many dying and those who survive experience total mental depletion. Burnout, depression and anxiety creep up onto touring DJs, especially on comedown from drugs, and this gets worse and worse with prolonged chemical abuse. On top of that, people in the industry do not seem to have proper support from experts, or refuse to listen until it’s too late.
A big problem in the music industry is that it is heavily populated with 2 high-risk groups- young, inexperienced people and people with previous mental health issues. Living such a high-paced life filled with dangerous temptations will quickly exaggerate mental disorders and on the other side overwhelm the young and developing mind, breeding many insecurities and mental struggles.
Having a public life is a very hard thing to deal with. The most notable example of this is Britney Spears’ breakdown. Though she is a pop star and not an electronic musician, this is quite relevant to this article, as Britney is a musician under heavy public scrutiny. She is a prime example how badly negative press can impact someone’s mental health. On top of that, she is still being controlled by her family and management to an extent. DJs are also heavily directed by their management and this often leads to them feeling powerless, even miserable.
i_o once mentioned in his Tweets how during the times of the pandemic, we can truly see how many people care for us. Those who do will check in on us daily and offer help in any form they can. Unfortunately, one of his last posts on instagram, with a caption “do u ever question ur life” wasn’t taken as a warning sign that he needs checking up on.
This documentary gives an insight behind the scenes and showcases interviews with iconic DJs, like Carl Cox, Pete Tong, Eric Morillo, Seth Troxler, Luciano and other, giving us an insight in how they feel being part of the business:
This second documentary is about the world’s “craziest” DJ, Fat Tony, who claims he had spent over a million pounds on drugs, during his 28 years of using. He clearly shows us how much problems drugs cause to DJs and multiply their mental health struggles:
This article is a reminder to frequently check on your loved ones and make action, don’t just leave them with a few empty words.
A relatively new invention will change the way we douse fires, in particular it will improve our approach to them.
Whenever something huge burns, we think only of a forest or building fire, the risk of sacrificing human lives is truly enormous and finding an alternative way to combat this problem would mean saving many lives.
Water, chemicals, flame inhibitors, fire extinguishers, aerosol suppressors are the most common ways to put out a fire, but still not the best and not usable for every situation.
A revolutionary way to put out a fire is definitely with sound waves. But how? Sound waves move oxygen away from the source of a flame and spread it over a larger surface. In this way the “fire combustion triangle” is broken, consisting of the three elements necessary for the combustion of the fire (heat, fuel and oxygen).
Without relying on other sources such as water and chemicals, the frequencies of these sounds are between 30 and 60 Hz.
The concept of using sound waves had already been studied by teams at West Georgia University and the US Defense Advanced Research Projects Agency, but without any success.
In 2015, two final year students from George Mason University in Virginia, USA, Seth Robertson and Viet Tran, created an acoustic fire extinguisher for their senior design project at George Mason University.
It was originally created to put out small fires in the kitchen, but currently the goal is to fight large fires.
They tested different frequencies of sound on small fires and found that the lowest frequencies, 30-60Hz, produced the desired effect.
The final prototype consists of an amplifier and a cardboard collimator to focus the sound, it is a portable device of only 9 kg, powered by the network, able to quickly extinguish small alcohol-powered fires.
They are currently working to move on to further testing and refinements and studying the feasibility of applying the principles. For example, it could be applied in space, where fire is a big deal, and it is possible to direct sound waves without gravity.
It contains no refrigerant and may not be able to prevent re-ignition after the sound has been turned off, but they are trying to improve it.
Resources:
PhysicsWorld: Dousing flames with low-frequency sound waves. 2015
DellTechnologies: Sound Waves to Fight Wildfires: How Does it Work?. 2020
Der Pisound verwandelt den Raspberry Pi in ein Musikinstrument, einen Effekt, einen Audiophilen Netzwerk Player, ein portables Recording Studio oder gar eine Internet Radio Sation. Es ist eine ultra-low latency Sound Card und Midi Interface, ausgestattet mit 192kHz 24-bit Stereo Input and Output.
Den Pisound kann man beispielsweise im Patchob OS verwenden. Eine Software, die quasi ein Pedal-Board simuliert. Die Software, die man über einen Browser öffnen kann, lässt verschiedenste Effekte und Signalwege Programmieren. Nicht nur für Audio, sondern auch für Midi. Die Einstellungen werden über eine Netzwerkverbindung synchronisiert. Die Sound Card eignet sich auch hervorragend dafür seine eigenen Pure Data oder Super Collider Patches laufen zu lassen.
Den Raspberry Pi und den Pisound werde ich schlussendlich nicht für mein Projekt verwenden, da er in einigen Bereichen schon fast zu komplex ist und viele Features hat, die ich gar nicht benötigen würde. Weiters habe ich die Erfahrung gemacht, dass man sich nicht immer 100 Prozent auf das Betriebssystem verlassen kann, sprich dass es richtig bootet usw. Auch der Kostenpunkt ist ein Ausschlussgrund, da ein solches Produkt nicht finanzierbar wäre, wenn man eine Sound Karte um 100 Euro + den eigentlichen Raspberry Pi verbaut.
Der vorgestellte Werbebeitrag ist eine vom Automobilkonzern Volkswagen Österreich veröffentlichte Produktion, welche von der Produktionsfirma Wuger Brands in Motion GmbH erstellt wurde. Es handelt sich um einen 1-minütigen Werbefilm über den neuen Touareg, in welchem der österreichische Schauspieler Tobias Moretti die Hauptrolle spielt. Das Video wurde am 15.03.2019 auf dem Youtube Kanal von Volkswagen Österreich hochgeladen, jedoch auch auf anderen Medien geteilt, da es als Fernsehspot betitelt wird. Etwa die Hälfte der Produktion ist mit dem Lied „Love Affair“ von der Gruppe „The Twain“ unterlegt.
Visuell
Ort des Geschehens ist eine verschneite, wolkenverhangene Berglandschaft. In der Anfangsszene durchquert ein Reiter/ Cowboy (Tobias Moretti) auf einem Pferd einen Fluss. Es werden verschneite Wälder als Luftaufnahmen gezeigt. In der zweiten Szene sieht man einen mittelalten Autofahrer in einem Touareg, leicht zufrieden grinsend durch den verschneiten Wald mit seinem Auto fahren.
Beide Szenen wechseln mehrmals, bis der Reiter mit seinem Pferd auf der Straße zum Stehen kommt, auf dem das Auto fährt. Das Auto muss bremsen und hält abrupt an. Fahrer und Reiter haben Blickkontakt. Der Fahrer des Touareg schaut ängstlich, wonach der Reiter ihm durch Kopfnicken vermittelt, aus dem Auto auszusteigen. Anschließend steigt er von seinem Pferd ab, hängt sein Gewehr an das Pferd und steigt in das Auto ein. Er begutachtet neugierig das Interieur, streichelt über das Armaturenbrett und stellt sich fast wie automatisch das Lenkrad ein. Er umfasst das Lenkrad, gibt Gas und fährt auf der verschneiten Straße davon, wobei er einen kleinen Blick in den Rückspiegel wirft. – Der neue Touareg – wird eingespielt. Zum Ende sieht man den Autofahrer neben dem Pferd stehen, beide schauen sich an, und die Schlusssequenz der Marke mit „Volkswagen“ beendet den Spot.
Audio
Dieser Werbespot ist etwa zur Hälfte mit Musik unterlegt. Der restliche Teil besteht aus Geräuschen und Sound Design Elementen. Es wird nicht gesprochen. Zu Beginn der ersten Szene ist ein Windrauschen zu hören, welches Kälte erzeugen soll, sowie das Wasserplätschern und Schneeknirschen von den Hufen des Pferdes. Alle Geräusche sind jedoch so klar zu hören und isoliert, dass sie mit großer Wahrscheinlichkeit in der Postproduktion eingefügt wurden. In den folgenden Schnitten zum Autofahrer wechselt der Sound von „kaltem“ Windrauschen zu „warmen“ gedämpften Motorengeräuschen, ohne Wind, also Kontrast des warmen Autos zur kalten winterlichen Berglandschaft. Als Fahrer und Reiter aufeinandertreffen, bremst das Auto ab, was im Bild unrealistisch schnell wirkt, und durch ein schnelles Abklingen des Motorengeräusches verdeutlicht wird. Es wird mit kleinen Details wie diesem unterschwellig (bei erstmaligem Anschauen kaum bemerkbar) eine Information über die gute Bremsleistung des Autos, selbst auf Schnee, suggeriert. Anschließend beginnt beim Augenkontakt der beiden Protagonisten das Lied „Love Affair“ im Chorus und steigt direkt im Text ein, welcher die Situation wie eine Narration beschreibt. „Boy, get out of my car, I feel like I don’t love you no more.”, wird gesungen während der Reiter dem Autofahrer per Nicken andeutet auszusteigen. Das Absteigen des Reiters wird akustisch durch Geräusche wie Klopfen, Schnauben des Pferdes und Windrauschen unterlegt. Dann nimmt die Musik zu und die Nebengeräusche werden leiser. Beim Einsteigen ins Auto sind „Streichelgeräusche“ und das Motorensummen des Lenkradverstellens zu hören, während die Stimme der Musik singt: „Boy now get out of my way, This could be our very last day. Im afraid of Love Affair. But I don’t care.”. Das Auto fährt mit röhrendem Motor los, während das Lied im Refrain mündet, dass durch ein Gitarrensolo und verzerrte Gitarrensounds sehr rockig und wild klingt. Auch die rockige Musik und der bearbeitete Motorensound beim Losfahren, sind kurze auditive Stilmittel, um die Informationen über das Auto so positiv wie möglich für eine bestimmte männliche Zielgruppe zu präsentieren. Das Gitarrensolo beendet die Sequenz und die typische gesprochene Markenstimme beendet mit „Volkswagen“ den Spot.
Ich habe außerdem Frequenz-, sowie Dynamik- und Lautstärkeanalysen durchgeführt, auffallend waren dabei der relativ hohe Anteil an tiefen Frequenzen unter 300 Hz, da diese den Bass des Motorengeräusches wiederspiegeln, sowie aus dem Lied (gespielter E-Bass) stammen. Es sind jedoch auch hohe Frequenzen bis knapp 20kHz vorhanden, die von den White Noise artigen Windgeräuschen und den Transienten der verzerrten Gitarren stammen. Der Klang ist also auf dem vollen Frequenzspektrum wahrnehmbar, hat aber auch genug hohe Frequenzen, um auf Lautsprechern ohne viel Bass ausreichend gehört zu werden. Die Dynamik- und Lautstärkeanalyse veranschaulicht sehr deutlich den Spannungsverlauf, und wie er durch die Musik und das Sounddesign gesteigert wird. In Sekunde 9 ist der erste Peak des Spektrums, welcher durch den ersten Autosound erzeugt wird. Dieser ertönt, wenn das Auto zum ersten Mal zu sehen ist. Abgelenkte Zuschauer werden sensibilisiert, die Aufmerksamkeit auf die Werbung und das Auto gerichtet. Ab Sekunde 20 fängt die Musik an zu spielen. In dem Graph erkennt man deutlich die Steigerung der Lautstärke und Dynamik, welche sich fast bis zum Ende des Spots steigert und so eine gewisse Spannung erzeugt. Die Lautstärke wurde nicht bis ans „Limit“ gemastert, sodass dem Lied noch etwas Headroom bleibt und es nicht zu unerwünschten Verzerrungen kommt.
Außerdem wird trotz der fehlenden Sprache und Musik am Beginn des Spots durch Sound Design wie Windgeräusche und Wasserplätschern genug Soundscape geschaffen, dass zu keinem Zeitpunkt kein Sound gespielt wird, sodass ein einheitlicher „Klangteppich“ entsteht und den Spot als eine Einheit wirken lässt. ______________________________________________________________________________
Der Werbespot von Volkswagen Österreich spricht meiner Meinung nach sehr gut die anvisierte Zielgruppe an. Die Wintersituation in den Bergen verstärkt den Eindruck, dass dieses Auto auch in widrigen Landschaften und schwierigen Wetterbedingungen ohne Probleme fährt. Der passende Text der Musik veranschaulicht die emotionale Beziehung, die Tobias Moretti als Reiter mit dem Auto sofort aufbaut, indem er von einer Liebesaffäre spricht, die ihn von seinem gewöhnlichen Leben auf dem Pferd wegbringt. Die Gestik und Mimik der Schauspieler in Kombination mit der Musik bedürfen keiner weiteren Erklärung oder Informationen, da die Emotionen durch Streicheln des Armaturenbretts oder den gedämpften Sound im Inneren des Autos herübergebracht werden.
Es wird, obwohl es sich um ein technisches Produkt handelt, wenig mit echten Informationen über das Produkt geworben, eher mit emotionalen, schauspielerbezogenen und filmischen. In diesem Fall ist die Musik auch keine Jingle oder eine Musik die typisch für Volkswagen steht, bis auf das kurze, wenn auch gesprochene, Soundlogo von „Volkswagen“. Nach telefonischer Auskunft der Produktionsfirma‚ ‚Wuger Brands in Motion‘, weiß ich, dass die Musik und der Text extra für den Spot komponiert wurden, wobei es mehrere Versionen des Liedes gab, bis das vollständige Endprodukt fertig war. Die Band, welche das Lied spielt, schreibt auch regelmäßig für andere Unternehmen Lieder. Der Musikstil passt durch die elektronisch, rockige Musik gut zu Technikwerbung und spricht durch sportliche Motorensounds hauptsächlich die jüngere, technikinteressierte Bevölkerung an. Trotz der düsteren kalten Stimmung der Bilder bringt die ‚energetische Musik‘ ein Kontrast, der nach Angaben der Produktionsfirma gewollt war. Sätze wie, „Im afraid of love affair, but i dont care …“, bringen unterbewusst Gedanken auf, die eine wilde spontane Zeit andeuten, welche sich viele Menschen wünschen. Der Spot ist nur eine Minute lang, trotzdem ist so gut wie jede Sekunde ausgenutzt und vollgesteckt mit unterschwelligen Informationen. Außerdem soll die dreiste, auch filmreif unrealistische Situation am Ende die Betrachter zum Schmunzeln bringen und eine positive Erinnerung hinterlassen.
Ich habe eine interessante Präsentation von den Leuten der Sound-Abteilung von CD Projekt RED zum Sound Design und der Implementierung mit Wwise gefunden.
Image processing and generating using machine learning has been significantly enhanced by using deep neural networks. And even pictures of human faces can now be artificially created as shown on thispersondoesnotexist.com. Images however are not that difficult to analyse. A 1024px-by-1024px image, as shown on thispersondoesnotexist, has “only” 1,048,576 pixels; split into three channels that is 3,145,728 pixels. Now, comparing this to a two-second-long audio file. Keep in mind that two seconds really can not contain much audio – certainly not a whole song but even drum samples can be cut down with only two seconds of playtime. An audio file has usually a sample rate of 44.1 kHz. This means that one second audio contains 44,100 slices, two seconds therefor 88,200. CD quality audio wav files have a bit depth of 16bit (which today is the bare minimum in digital audio workstations). So, a two second audio file has 216 * 88,200 samples which results in 22,579,200 samples. That is a lot. But even though music or in general audio generation is a very human process and audio data can get very big very fast, machine learning can already provide convincing results.
Midi
Before talking about analysing audio files, we have to talk about the number one workaround: midi. Midi files only store note data such as pitch, velocity, and duration, but not actual audio. The difference in file size is not even comparable which makes midi a very useful file type to be used in machine learning.
FlowMachines is one of the more popular projects that work with midi. It is a plugin for DAWs that can help musicians generate scores. Users can choose from different styles to sound like for example the Beatles. These styles correspond to different trained models. FlowMachine works so well that there is already commercial music produced by it. Here is an example of what it can do:
Audio
Midi generation is a very useful helper, but it will not replace musicians. Generating audio on the other hand could potentially do that. Right now, generating short samples is the only viable way to go and it is just in its early stages but still, that could replace sample subscription services one day. One very recently developed architecture that seems to deliver very promising results is the GAN.
Generative Adversarial Networks
A generative adversarial network (GAN) simultaneously trains two models rather than one: A generator which trains with random values and captures the data distribution, and a discriminator which estimates the probability that a sample came from the training data rather than the generator. Through backpropagation both networks continuously enhance each other which leads to the generator getting better at generating fake data and the discriminator getting better at finding out whether the data came from the training data or the generator.
An already very sophisticated generative adversarial network for audio generation is WaveGAN. It can train on audio examples with up to 4 seconds in length at 16kHz. The demo includes a simple drum machine with very clearly synthesized sounds but shows how GANs might be the right direction to go. But what GANs really have to offer is the parallel processing shown in GANSynth. Instead of predicting a single sample at a time which autoregressive models are pretty good at, GANSynth can process multiple sequences in parallel making it about 50,000 times faster than WaveNet.
Wii Remote, or Wiimote, is the controller of Nintendo’s Wii console, which has occupied an important place in the gaming industry since 2006.
It’s a wireless controller with motion sensing and traditional controls.
The Wii Remote only uses an accelerometer to detect movement. Other functions, such as using it as a pointer, rely on an infrared sensor that tracks the position of a “sensor bar” above or below the television.
The accelerometer is an Analog Devices ADXL 330 and has three times the sensitivity of gravity.
It not only detects motion, but also reports the angle at which the Wiimote is held when it is not in motion – and not just one angle, but three: vertical, horizontal and rotational.
There are obviously many accessories, among them, we can find Wii MotionPlus, an accessory that uses a more precise and sensitive gyroscope, a device that measures orientation and angular velocity.
But now… can we use to as a controller for our virtual instrument?
Well, yes.
It is normally paired via Bluetooth, so this allows us to easily connect it to our computer.
Of course, we have to convert the Wiimote data streams into a module that our software can control, and we have several options for this.
On the Windows platform we can find GlovePIE, a free scripting language from Australian programmer Carl Kenner. It is fascinating for musicians because it includes a set of MIDI commands that work via the Windows MIDI Mapper and also commands for Open Sound Control (OSC), the communication protocol for sound and media processing.
Or we can access the data with Pure Data (Pd), an open source visual programming language. We just need to download the external like WiiSense and wiimote.
Here are some cool examples:
Resources:
E. Wong, W. Youe, C. Choy: Designing Wii controller: a powerful musical instrument in an interactive music performance system. 2008.
Wikipedia: Nintendo Wii
Sound on sound: Nintendo’s Wii Remote As A MIDI Controller