Aphex Twin is one of the most influential and important contemporary electronic musicians.
He is famous for his experimentations for for his unique style, where he combines elements from all kind of genres, mainly electronic genre, using atypical solutions/rythms to create a song.
His face, grinning or distorted, is a theme of his album covers, music videos and songs. He said it began as a response to techno producers who concealed their identities, as he stated:
“I did it because the thing in techno you weren’t supposed to do was to be recognized and stuff. The sort of unwritten rule was that you can’t put your face on the sleeve. It has to be like a circuit board or something. Therefore I put my face on the sleeve. That’s why I originally did it. But then I got carried away.”
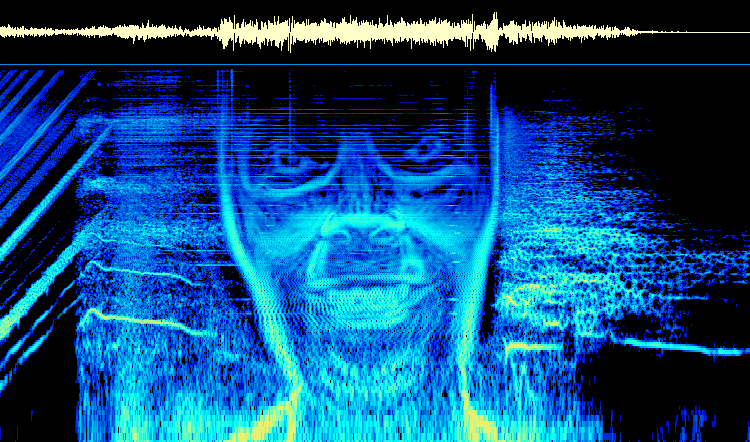
He even put it on a song. On the second track, easily called just “Formula”, from the album Windowlicker, if we open it with a Spectrogram visualizer we will be able to see his face with his typical grin.
Even if it looks like something really hard to do it. At that time, 1999, there was a Windows program called Coagula that could transform any picture into soundwaves with minimum effort. Aphex Twin himself had used a Mac program called Metasynth to do his images.
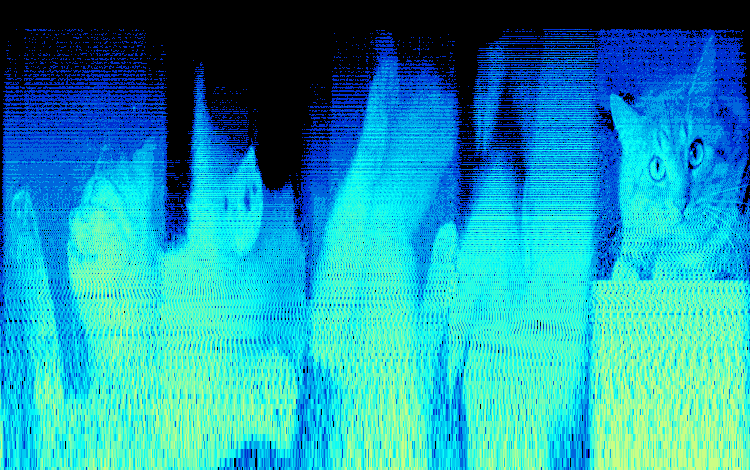
He used the same technique to the first track of the album with this aural image.
This was also something that some other artists made on the same year, here some other example:
Atau Tanaka is a composer and performer of live computer music and, at the same time, Digital Media professor at Newcastle University.
He was born in Tokyo but he soon moved with his family to America where he then studied Biochemistry and, later music.
At Stanford he studied Computer Music and then continued research at the IRCAM in Paris. Later he was Artistic Ambassador for Apple France, then researcher at Sony Computer Science Laboratory Paris, and was an Artistic Co-Director of STEIM ( Studio for Electro-Instrumental Music) in Amsterdam.
Tanaka had the fortune of attending lectures by John Cage, who according to him was one of the first musicians to have a strong conceptual approach.
As Tanaka says “He made contact with the visual art world”.
His research is in embodied musical interaction. Also intersection of human computer interaction and gestural computer music performance.
This includes the use of physiological sensing technologies, muscle tension in the electromyogram signal, and machine learning analysis of this data.
On the other hand, he studies user experience through ethnographic methods of participatory design where activities of workshopping, scenario building, and structured brainstorming lead an understanding of a mediums affordances in bottom-up, emergent ways.
EAVI (Embodied AudioVisual Interaction) is a research group of which Atau belongs, which focuses on embodied interaction with sound and image. This group carries out research across topics including motion capture, eye tracking, brain computer interfaces, physiological bio-interfaces, machine learning, and auditory culture.
Another group that features Atau Tanaka is Sensorband, a trio of musicians using interactive technology. Gestural interfaces – ultrasound, infrared, and bioelectric sensors as musical instruments. The other two members are Edwin van der Heide and Zbigniew Karkowski.
Atau plays the BioMuse, a system that tracks neural signals (EMG), translating electrical signals from the body into digital data.
Edwin plays the MIDIconductor, machines worn on his hands that send and receive ultrasound signals, measuring the hands’ rotational positions of and relative distance.
Zbigniew activates his instrument by the movement of his arms in the space around him. This cuts through invisible infrared beams mounted on a scaffolding structure.
They literally bring a visceral physical element to interactive technologies.
He also did many installations, one of them is Global String, launched this installation in Rotterdam’s fifth bi-annual Dutch Electronic Arts Festival and made in cooperation with the Ars Electronica Center in Linz
Global String is a multi-site network music installation, connected via the internet, It is a musical instrument where the network is the resonating body of the instrument, by use of a real time sound synthesis server.
As he stated:
“The concept is to create a musical string (like the string of a guitar or violin) that spans the world. Its resonance circles the globe, allowing musical communication and collaboration among the people at each connected site. The installation consists of a real physical string connected to a virtual string on the network. The real string (12 millimetres in diameter, 15 metres in length) stretches from the floor diagonally up to the ceiling of the space. On the floor is one end-the earth. Up above is the connection to the network, to one of the other ends somewhere else in the world. Vibration sensors translate the analog pulses to digital data. Users strike the string, making it vibrate.”
Here are some link to other works:
Bondage (Sonification and remix of a photo by Araki)
Biomuse (Biosignal sensor instrument performance)
Myogram (8 channel sonification of muscular corporeal states)
References
ataut.net
Music Hackspace – Atau Tanaka: Making music with muscle sensors
Goldsmiths University of London – Prof Atau Tanaka
In this blog post, I would like to write about a fairly unusual movie soundtrack to find, the Birdman soundtrack or (The Unexpected Virtue of Ignorance).
Birdman is a 2014 American comedy-drama directed by Alejandro G. Iñárritu.
Here is a small summary, just to know what it is:
“Riggan Thomson is an actor who played the famous and iconic superhero” Birdman “over 20 years ago. Now, in his middle age, he is directing his Broadway debut, a drama called “What We Talk About When We Talk About Love,” an adaptation from a Raymond Carver story. With the help of his assistant and daughter Sam, and his producer Jake, he will play premieres of the show, even when a talented actor he has hired, Mike Shiner, acts arbitrarily, the internal issues between him and the other cast, the his futile utmost efforts to critics and the unexpected voices of his old character, the Bird Man, pushing his sanity to the first debut show. [1]
Besides the movie itself, what I find really interesting is the soundtrack.
There are several classical music pieces, mainly from the 19th century (such as Mahler, Tchaikovsky, Rachmaninov, Ravel) and several jazz compositions by Victor Hernández Stumpfhauser and Joan Valent. But those are just “outlines” of the real thing.
Most of the score consists of a drum score composed entirely of solo jazz percussion performances by Antonio Sánchez.
It’s a rather unusual choice for a film, as the drums are just a percussion instrument, no harmony, (almost) no melody.
But why? As the director said:
“The drums, for me, were a great way to find the rhythm of the film … In comedy, rhythm is king, and not having the editing tools to determine time and space, I knew I needed something. that would help me find the internal rhythm of the film. “
When the director contacted Sánchez and offered him to work on the film, the composer felt a little unprepared and surprised, as he put it:
“It was a scary proposition because I had no benchmarks on how to achieve this. There is no other film that I know of with a soundtrack like this.” Sánchez hadn’t worked on a movie before either.
He first composed “rhythmic themes” for each of the characters, but Iñárritu preferred spontaneity and improvisation when he said, “Man, this is absolutely the opposite of what I was thinking. You’re a jazz musician. I want you to. you have a completely jazzy approach, which improvises, which has nothing too preprogrammed. I just want you to react to the story.” [2]
After Sánchez visited the set for a couple of days to get a better idea of the film, he and Iñárritu went to a studio to record some demos. During these sessions the director first spoke to him through the scene, then as Sánchez improvised he guided him by raising his hand to indicate an event – such as a character opening a door – or describing the rhythm with verbal sounds. They recorded about seventy demos and, once they finished shooting, they put them in the rough cut.
He liked the way the soundtrack complemented the action, but not how the drums actually sounded. Having been recorded in a New York studio, the audio was extremely crisp and clear, not quite the mood they wanted for a film steeped in tension and dysfunction.
So Sánchez headed to Los Angeles to re-record the tracks.
They wanted “rusty, out of tune drums that hadn’t been played in years”. Also, Sanchez purposely degraded his kit. “I didn’t tune the drums, I used mismatched heads, stuck duct tape on the heads to make them weaker, and put things on the cymbals to make them sound a little broken. I also stacked two and three plates on top of each other, metal on metal. Instead of a sustained sound, you get a dry, trashy one. It worked a lot better.”
Iñárritu also pressured his sound design team.
In these scene they pass a drummer on the sidewalk outside the theater. The drum sounds change multiple times during the sequence — first when Keaton leaves the quiet of the theater and exits onto the New York City street, then again as he and Norton approach and move past Smith. Iñárritu wanted the volume level of the sidewalk drummer to rise and fall as Keaton and Norton walked by, but they did it in the most authentical way.
“We actually brought the drums out onto the street near the studio,” Sanchez recalls. “There were a couple of sound guys a block away with mics that had really, really long cables. I started playing, and they walked the whole block, right pass my drums, and kept walking to the next block. Then they came back. That’s how Alejandro approaches his work. Anybody else probably would have just turned the volume up and down.”
“The movie fed on the drums, and the drums fed on the imagery”.
The official soundtrack was released as a CD (77 min) in October 2014, and as an LP (69 min) in April 2015.
It won the Grammy Award for Best Score Soundtrack for Visual Media.
This might be interesting for all of you who want to do a live performance! 🙂
Setlist manager, digital mixer, software instrument and effects host, PDF sheet music player, multitrack audio player and highly advanced patchbay and MIDI router, these are the features of this new live performance software, Camelot, developed by Audio Modeling.
It is also designed not to have the need to have a manual, everything is clear and with just a quick guide you can have access to all the features.
As they stated:
“Camelot is an application created to address the most complex live performance needs with a simple and guided workflow. What in the past could only be achieved with a complex configuration of several applications and devices connected together, Camelot achieves in a single comfortable and well-designed workstation. Song in Camelot gathers all your configurations of hardware instruments and MIDI routing, software instruments and FX instances, sheet music and audio backing tracks.
It is also quite cheap for all of its features and there is also a free version, in which only a few features are missing.
Bela is an open-source embedded computing platform for creating responsive, real-time interactive systems with audio and sensors.
Bela was born in the Augmented Instruments Laboratory, in the Centre for Digital Music at Queen Mary University of London. Bela is now developed and produced by Augmented Instruments Ltd in London, UK.
It provides low latency, high quality audio, analog and digital I/O in a really small package that can be easily embedded into a huge range of applications.
It can be used, for example, to create musical instruments and audio effects.
It is built on the BeagleBone family of open-source embedded computers, Bela combines the processing power of an embedded computer with the timing precision and connectivity of a microcontroller.
In computing, “real-time” refers to any system that guarantees response within a specified time frame. This is called the “real-time constraint”. Bela’s real-time constraint is processing audio frames at audio rate, which is 44,100 frames per second.
There are different types of real-time systems, often called soft, firm, or hard. A firm or soft real-time system can miss a few deadlines, but performance will degrade if too many deadlines are missed. A hard real-time system is one that is subject to stringent deadlines, and must meet those deadlines in order to function. Bela is a hard real-time system, meaning that it must process audio frames at audio rate in order to function.
Bela features an on-board IDE that launches right in the browser, making it easy to get up and running without requiring any additional software.
It has just 0.5ms latency while retaining the capabilities and power of a 1GHz embedded computer running Linux.
Why choose Bela? Because no complicated setup or complex toolchains is needed. Just connect Bela to your computer, launch the on-board IDE in a web browser, and start coding right away.
Bela comes in 2 version, Bela Board and Bela Board mini.
Bela Board has 8 channels of 16-bit analog I/O, 16 digital I/O, stereo audio I/O, and 2 built-in speaker amplifiers.
Bela Mini is 1/3 the size of the big one. It features 8 16-bit analog inputs and 16 digital I/O, as well as 2 channels of audio input and output.
It runs a custom audio processing environment based on the Xenomai real-time Linux extensions. Your code runs in hard real-time, bypassing the entire operating system to go straight to the hardware.
What’s really great, is that you can code in various languages such as C++, SuperCollider, Csound and PureData. This makes it really user-friendly!
Bela is ideal for creating anything interactive that uses sensors and sound. So far, Bela has been used to create:
musical instruments
kinetic sculptures
wearable devices
interactive sound installations
effects boxes
robotic applications
sensorimotor experiments
paper circuit toolkits
e-textiles
Here some examples:
Light Saber
of Nature and Things – de Shroom (the Shroom) – Sound Art Installation
Microtonal subtractive synthesizer (Bela Mini + Pure Data)
SoundInk (Bela Mini + Pure Data)
Noise do not Judge (Bela, Trill Craft + Pure Data)
Music for Solo Performer is a composition from the american composer of experimental music Alvin Lucier.
Mr. Lucier was a music professor at Wesleyan University in Middletown, Connecticut and also a member of the influential Sonic Arts Union (a collective of experimental musicians).
His works explore acoustic phenomena and auditory perception and is influenced by science and explores the physical properties of sound itself: resonance of spaces, phase interference between closely tuned pitches, and the transmission of sound through physical media.
He is mostly know for the piece “I am sitting in a Room” from 1969, in which he plays with the resonence of different rooms.
But the proper beginning of his compositional career is defined by his 1965 composition Music for Solo Performer.
This composition is also reffered to as the ‘brain wave piece’ and is considered to be the first musical work to use brain waves to directly generate the resultant sound..
The mechanics of the piece were although simple: alpha brain waves are picked up from electrodes attached to the performer, and the low frequency thumps (typically between 9-15 hertz) are first sent into amplifiers to amplify the pulses’ volume. Then, a bandpass filter cleans up the signal, which is sent by a second performer at a mixing board through a number of loudspeakers attached to percussion instruments and other objects to be activated by these massive, low frequency thumps.
This work, anyway, doesn’t attempt to use or show mind controll, but more like how to creatively use the mind controlling the “consequencies”, as Luier said:
“The idea was that I didn’t want to show mind control… Discovery is what I like, not control… So I completely eschewed that form… and let that alpha just flow out, and the composition was then how to deploy those speakers, and what instruments to use.”
How does this performance look like?
A man sits in a chair in the middle of a concert hall, perfectly still and dressed in a suit and tie, surrounded by a veritable orchestra of percussion instruments. Timpani, gongs, bass and snare drums and cymbals without performers to bring them to life.
Out of nowhere, thunderous bass sounds bring these instruments into vibratory oscillation, their sonic activity spreading around the space in an ever-morphing wash of sound. The man sits calmly at the center. His eyes are closed as he listens to this remarkable spectral orchestra, which, is being played by his brain.
How did this idea start?
In 1964 Lucier was teaching at Brandeis University and he was trying to find his own path, to work on composition, on his own language.
At the time, physicist Edmond Dewan was working at a lab near Brandeis doing brain wave research for the US Air Force. Dewan was an amateur organist and used to visit the Brandeis music department and was eager to share his ideas and equipment. Also, Lucier spent many hours working alone in the Brandeis electronic music studio working with Dewan’s gear such as two Tektronix Type 122 preamplifiers in series, one Model 330M Kronhite Bandpass Filter set for a range of 9 Hz to 15 Hz, an integrating threshold switch and electrodes.
After learning how to produce alpha waves quite consistently, Lucier had to decide what he was going to do with them. They are between 10-14 hertz (below the normal human hearing range) so they could be somehow perceived as physical rhythmic impulses. His colleagues suggested that he could record the alpha waves and create a piece of tape with the material by manipulating the recording. But Lucier regularly used a recorded track of accelerated alpha waves during the performances of the piece to bring the waves into the audio range, the main material of the piece remains raw alpha generated in real time.
This work was also influenced by the strong impression that a Trappist monk’s meditation practice made on Lucier:
“I remember going into the chapel and watching a Trappist monk in the act of contemplation… he was thinking – deeply. It looked like somebody just thinking as hard as he possibly could. I remember I went back an hour later – he was in the same attitude – and I thought, “Well, if there’s any such thing as pure thought, that guy is doing it.” And that impressed me a lot… So when I did the brain wave piece, you’ve got to sit and not think of anything; because if you create a visual image your alpha will block.”
Here is a video of the performance:
Resources
Volker Sraebel, Wilm Thoben – Alvin Lucier’s Music for Solo PerformerExperimental music beyond sonification
Wikipedia – Alvin Lucier
Wikipedia – Sonic Arts Union
Andrew Raffo Dewar – Inner Landscapes Alvin Lucier’s Music for Solo Performer
In this interesting article by Michel Chion [1] we can find the 3 main ways of listening.
What is a listening mode? Well, when we listen to some event we are likely to notice different things, and this changes from situation to situation. The way we perceive things at an exact moment is a way of listening. Even if the event is the same, the listening mode may be different because it depends on many other factors.
The first listening modality described in Chion’s article is causal listening.
This means listening to gather information about its cause.
This type of listening mode can be associated with multimodal perception, because we intend to try to discover the sound source thanks to our previous knowledge and current circumstances.
If the source is visible, the sound provides information about it, if it is not visible we would try to identify it with our knowledge or logical predictions, but out of context, it is difficult to clearly identify the source.
It is also associated with audio / video synchronization, which makes us believe that a certain sound is being produced by a certain source.
Even if we cannot identify the source of an event, for example a scraping noise, we are still able to follow is “evolution” = acceleration, slowdown… (changes in pressure, speed and amplitude).
The second is semantic listening, listening to interpret a language or a code.
It is a kind of linguistic listening, but it also applies to auditory icons and all other sounds that communicate a specific message.
This works in a complex way, as it is purely differential.
As mentioned in the text: “A phoneme is heard not strictly for its acoustic properties, but as part of a whole system of oppositions and differences. Thus, semantic listening ignores notable differences in pronunciation (and therefore in sound) if they are not differences pertinent to the language in question. Linguistic listening in both French and English, for example, is not sensitive to some very different pronunciations of the phoneme a”.
One listening mode does not exclude another. We can listen to a single event using, for example, causal and semantic modes at the same time.
The last is reduced listening, whose name is attributed to Pierre Schaeffer, French composer, engineer and writer, founder of the Groupe de Recherche de Musique Concrète (!).
This mode does not depend on the cause or meaning of the sounds, it just focuses on the traits themselves.
We can in some ways associate musical listening and analytical listening, even if more specific, because it tends to analyze only one characteristic of the sound (height, amplitude…).
You have to listen to the event many times to analyze all the characteristics of the sound, this means that the sound must be recorded.
For example, when we identify an interval between two notes (paying attention to the pitch) we are using reduce listening.
This mode has the advantage of “opening our ears and sharpening our listening skills”. The aesthetic value of sound is not only linked to its explanation, but also to its qualities, to its “personal vibration”.
Pierre Schaeffer thought that the acousmatic situation could favor this way of listening. The acousmatic situation is a situation in which the sound is heard without seeing the cause.
Yet the results of some tests have shown the opposite. The first thing we try to do is always try to understand the source of the sound and what that sound might be. It takes several plays of a single sound to allow us to gradually perceive its features without trying to understand the cause.
I would also like to mention a few other forms of listening that come to mind as I write this post.
The first is emotional / instinctive listening, which is not mentioned in Chion’s article, but is somehow associated with analytic listening, which brings us back to reduced listening. In reduced listening you should really focus on determining the sound traits, but in instinctive listening you can clearly and immediately understand the traits of sound that are important to you, due to the emotional characteristics, of course.
Then empathic listening, which applies when we listen to someone talking, and we try to understand their feeling and emotion.
I think our mindset also determines how we will understand information, plus if we are already prejudiced about what we will hear we would have some sort of selective listening. This is not good, because we will filter the information to reinforce our bias.
Title: Digital Simulation and Recreation of a Vacuum Tube Guitar Amp
Author: John Ragland
Academic degree: Degree of Master of Science
Place & date: Auburn, Alabama, May 2, 2020
I chose this work, because it could be a relevant thesis to the topic I might want to address in my Master thesis.
Level of design
The design level of this work is quite good. The lists and the standardization of the structure make the work really easy to read and understand.
Degree of innovation
While it’s a pretty cool theme, it’s not that innovative. It is a field that has been studied before, and although the model he has chosen to recreate is quite interesting, it has already been done. However, the results are positive and important for this field.
Independence
It is not so easy to assess its independence. Since it is only practical / technical work and the author had to do everything himself (and of course with the help and suggestion of the tutors) I would say that he is quite independent.
Outline and structure
This work is well structured, everything is clear and it is easy to scroll through the pages. There is just a bit of confusion in the structure of the index, where sometimes the chapters are written not in the right chronological order, and this bothers me a little.
Degree of communication
It is really clear. The list of abbreviations at the beginning of the work makes everything immediately clear. Explaining all the terms in the beginning helps a lot to avoid wasting time looking for them somewhere in the text.
I think that even those who are not an expert could follow this work and understand it (even if not 100%, due to a technical / specific mathematical procedure). The support of images and diagrams helps a lot to visualize the whole process.
Scope of the work
The work is about 48 pages. I would consider it a bit too short for a master thesis. The process is really well explained, but perhaps some theoretical themes or previous work could have been described in more depth.
Orthography and accuracy
Except for some space or quotation mark errors, there are no grammatical errors. The sentence structure is also well done.
Literature
I would say there is a good amount of literature. Most of them are not online sources and all are specialist publications.
Piezo microphones are also called contact microphones, this means that they are attached to a surface and can perceive audio vibrations through it. They are not sensitive to air vibrations, but only transduce the sound transmitted by the structure.
They have many applications, they are used to detecting drums hits, to trigger electronic samples or even underwater. For these applications they work fine.
They are often used to amplify acoustic musical instruments, and this is where the problems begin.
Contact microphones are not well-matched to typical audio inputs. They cannot drive a 50 kilohm input, which is the typical line input.
Most Piezos are tuned speaker elements used in reverse, the microphone is glued to a brass disc designed to resonate between 2-4kHz so that with a small power input you get a great audio output.
The problem is that they are often paired with a standard audio load, which normally loses low frequencies.
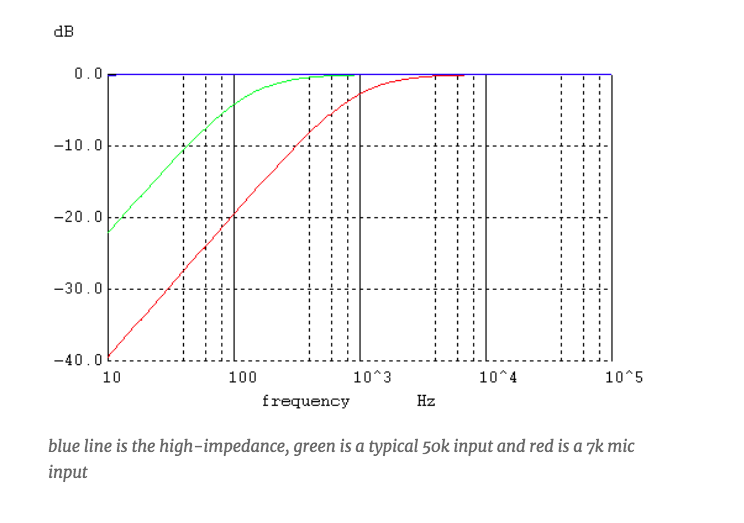
The Piezo sensor presents its signal through a series capacitance of approximately 15nF. When connected to a regular 50 kilohm line input, this forms a 200 Hz high pass filter, so here’s the main problem!
And, when connected to a consumer plug-in microphone input with an impedance of about 7 kilohms, the result is a 1kHz high-pass filter.
This should be inserted into a load that is higher than the impedance of the series capacitor at the lowest frequency of interest. If this is 20Hz, since the capacitor impedance is 1 / 2pifreq * C, then it should be above 530k.
This means that a high impedance input gets the blue line in the graph above.
Maybe you might think about EQing it later, but you will also start increasing the noise and hum at low frequencies.
IR, an old term for professional producers, but also studio owners, has today found its way from studio rooms to stages and even to the musician’s live equipment.
What is that? It is a sonic measurement of the sound of a speaker, room or microphone in relation to a sound source. [1]
Well, more detailed, it is the output of a dynamic system (a system that depends on the past and future value of the signal at any instant of time) when a impulse (short input signal) is presented.
So this “system” could be an electronic current, an economic calculation or a sound.
For example, Impulse Responses (IR) are used as a “replacement” for a guitar or bass speaker, both to digitally record the instrument without having to mic a real cab, and in a live situation, going directly to PA. Also, no microphone, no cab and, more or less, always the same sound.
There are several things that need to be taken into consideration when thinking about creating / choosing an IR. Many things affect the sound such as the type of speaker, the space we are in, which microphone we are using, its location, the microphone preamp and many other things.
With an IR you can capture all of this information, so you can instantly recall that setting.
An IR is normally a .wav file, and you can find a lot of them online, many companies / studios are releasing theirs, to let you have their tone.
How to use them? Simply load them with an IR Loader into your DAW (Use Space designer in Logic or there is the free VST IRLoader from LePou) or hardware (e.g. modeling amps like Kemper, AX FX, Line6 Helix).
Another use is with Convolution Reverb. CR is a simulation of a reverb or sound quality of a space using IRs. How? A short sound is played, the response is then measured and recorded, then recreated using algorithms. Some CR plugins are Space Designer (included in Logic Pro) or Waves IR1.