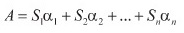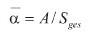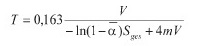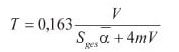Da ich im letzten Semester mit der Planung des Audiostudios der FH Joanneum beaufragt wurde, kam mir zunächst die Idee die Nachhallzeit der geplanten Umsetzung zu kalkulieren. Allerdings ist mir bei der Recherche nach einem geeigneten Tool aufgefallen, dass es keine kompakte Applikation gibt, die dies ermöglicht. Es gibt zwar komplexe Simulationssoftwares wie EASE der Firma AFMG Technologies GmbH, bei denen die Nachhallzeiten in einem 3D-Modell ermittelt werden und das Nachbauen eines Raumes mit einem großen Zeitaufwand verbunden ist, diese Softwarelösungen sind aber verhältnismäßig teuer und nicht im Sinne einer schnellen Nachhallzeitberechnung. Da ich mich außerdem in meinem Project Work mit der Programmierung von Unity-Skripten in der Programmiersprache C# beschäftigt habe und tiefgreifendere Kenntnisse in dieser Sprache erlernen wollte, kam ich in den letzten Semesterferien auf die Idee, eine solche Applikation selber zu schreiben, um bei zukünftigen Projekten Nachhallzeitkalkulationen anbieten zu können. Außerdem wäre es in naher oder ferner Zukunft auch im Interesse aller Akustiker und Audioenthusiasten, eine solche Software zu veröffentlichen.
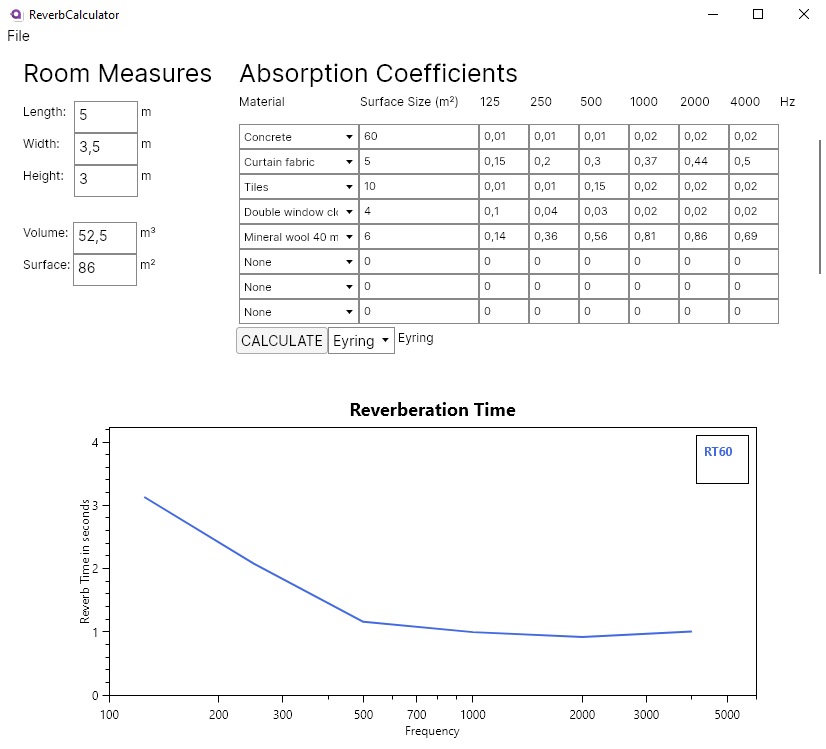
Grundsätzlich funktioniert die Applikation so, dass man zunächst die Maße des (rechteckigen) Raumes eingibt. Daraus wird das Volumen und die Oberfläche ermittelt, die für die spätere Kalkulation benötigt wird. Man wählt daraufhin das Oberflächenmaterial aus, aus welcher die Wände, Decken und Böden bestehen. Für die verschiedenen Materiale werden Oberflächengrößen eingegeben, die auch für die Kalkulation benötigt werden. Im unteren Teil der Applikation wird nun nach dem Betätigen des “CALCULATE”-Buttons die Nachhallzeit in einem Graphen ausgegeben.
Prototyp des Programms
Behind The Scenes
Das Programm habe ich mithilfe des C#/XAML-Frameworks Avaloniageschrieben, das auf der Syntax des .NET-Frameworks WPF aufbaut, das für für User Interfaces entwickelt wurde. Der Unterschied zu WPF ist allerdings, dass Avalonia cross-platform ist und somit auch auf anderen Betriebssystemen als Windows ausführbar ist. Zusätzlich habe ich für die Applikation das MVVM-Konzept verfolgt, welches das User Interface streng von der Programmlogik und der Datenbank trennt. Dies ermöglicht in Zukunft leichtere Eingriffe in die verschiedenen Teilaspekte des Programms, wie z.B. des User Interfaces, ohne die Programmlogik verändern zu müssen.
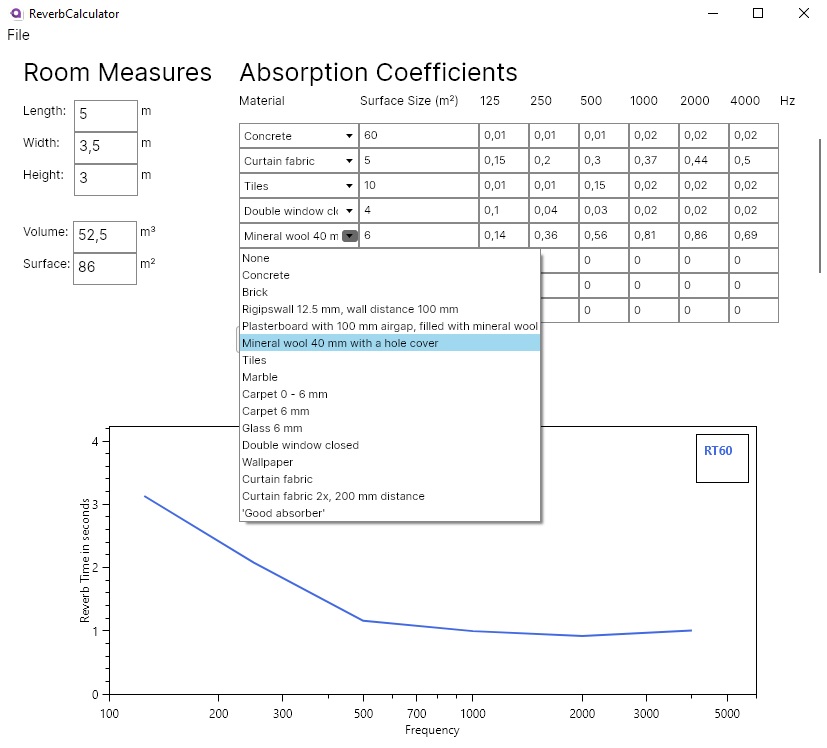
Die Auswahl der Oberflächenmateriale geschieht über ein Dropdownmenü, welches eine Liste verschiedener Materiale aus einer aktuell noch provisorisch angelegten Datenbank ausgibt.
Dropdown-Liste mit unterschiedlichen Materialen
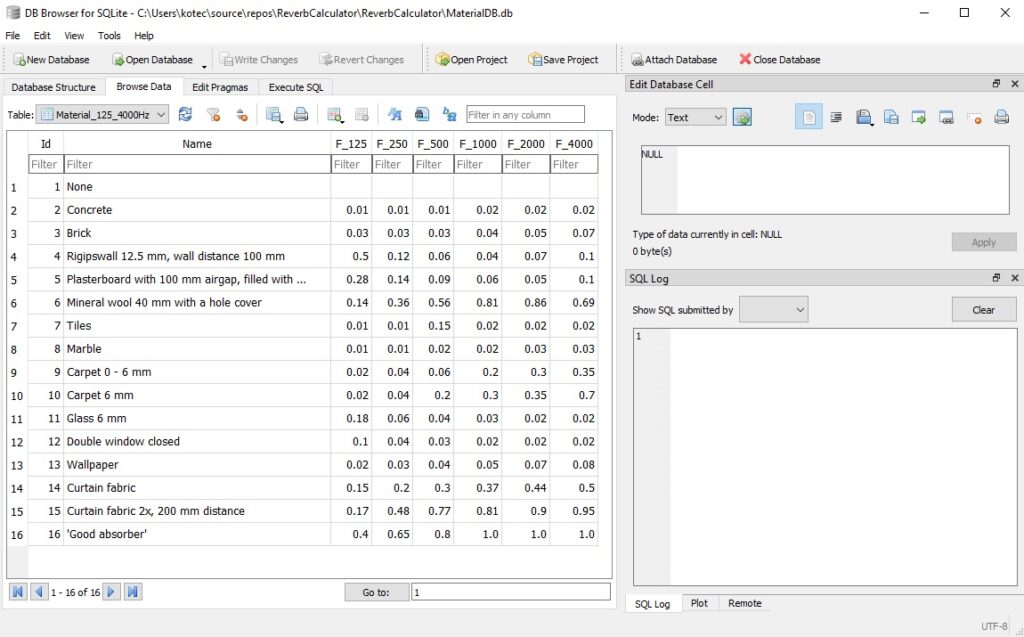
Die Datenbank wurde mittels SQLite angelegt und in das Programm implementiert. SQLite ist eine kompakte SQL-Lösung, die sich hervorragend für lokal angelegte Datenbanken eignet und ohne Webserver auskommt.
Datenbank mit Materialen in SQLite
Der Kern der Kalkulation basiert auf statistischen Nachhallzeitberechnungen nach Eyring bzw. Sabine, die ich in einem meiner früheren Blogposts bereits behandelt habe. Man kann manuell zwischen der Berechnung nach Eyring bzw. Sabine auswählen. Graphisch wird die Nachhallzeit mit dem .NET-Framework OxyPlot, das praktischerweise auch mit Avalonia kompatibel ist, ausgegeben.
Das Programm funktioniert bereits im Kern, es gibt allerdings noch einige Sachen, die überarbeitet und verfeinert werden müssen für eine professionelle Nutzung:
Erweiterung der Bänder der Absorptionsgrade von Oktavbändern von 125 – 4000 Hz auf Terzbänder von 50 – 8000 Hz
Option zum Umschalten zwischen 125 – 4000 Hz und 50 – 8000 Hz
Automatische Auswahl zwischen der Eyring und Sabine-Berechnung je nach gemitteltem Absorptionsgrad
Manuelle Skaliermöglichkeiten des Graphen
Plotten des Graphen als PDF oder JPEG
Vergleich von Graphen mit verschiedenen Oberflächenkonfigurationen
Fehlermeldung bzw. Warnung, wenn Oberflächen der Materiale größer sind als die gesamte Raumoberfläche
Speicher- und Lademöglichkeit der Raumkonfiguration und der Berechnung
Manuelles Einpflegen und Speichern von Materialdaten
Auslesen von Materialdaten aus Excel-, CSV-Tabellen und SQL Datenbanken.
Die vorliegende Masterarbeit von Svea Laura Benad folgt den Konzepten des “Sonic Branding”, der Einbeziehung von Klang zu Markenzwecken, und der “Corporate Auditory Identity”, die als das auditive Gegenstück einer visuellen Unternehmensidentität verstanden werden kann. Untersucht wurde der Einfluss der Konsistenz von Branding-Strategien und des Einsatzes von visuellen, auditiven und audiovisuellen Elementen auf wünschenswerte Branding-Ziele für neue Marken, wie z.B. Markeninteresse, emotionale Markenbindung und Verbraucherbindung.
Die Gestaltungshöhe war meiner Meinung nach gut, da sehr umfangreich die Literatur behandelt wurde. Es wurde theoretische Gerüst bestand dabei aus Corporate Identity, Sonic Branding, Consistency in Branding Strategies, Brand Interest und Emotional Brand Attachment. Dabei war der Innovationsgrad in der Umsetzung des Experiments meiner Meinung nach auch vorhanden, durch ausgeklügelte Designs für Social Media Anwendungen. Das Thema ist zwar schon oft erforscht, aber noch immer aktuell.
Das Experiment wurde für meinen Erkenntnisstand Selbstständig erarbeitet, es ist keine Hilfe von außen direkt erkennbar. Die Gliederung und Struktur sind für mich nachvollziehbar und strukturiert. Das Einzige was mir fehlt ist ein Inhaltsverzeichnis. Die Autoren erklärt das Themengebiet sehr gut und geht auf viel Literatur ein. Der Umfang der Arbeit ist meiner Einschätzung nach ausreichend für eine Masterarbeit mit über 60 Seiten und einem Werkstück.
Sonst wurde die Arbeit ausreichen dokumentiert und es wurde sorgfältig und genau gearbeitet. Die Literatur ist am Ende zu finden und es sind ausreichen Quellen verwendet worden.
Literatur:
Benad, S. L. (2016). The Effectiveness of Sound in Corporate Branding. Masterthesis. University of Amsterdam. Amsterdam.
“Video game genres and their music” by Pieter Jacobus Crathorne supervised by Prof. Winfried Lüdemann submitted at University of Stellenbosch in the Department of Music in March 2010
I chose this specific thesis as this was the main inspiration for my bachelor’s thesis, and because I have been a fan of computer games and been fascinated by their music for over fifteen years.
Design:
Although this thesis was written in the general field of art & design, it is not styled in an outstanding or revolutionary way. I can imagine the University of Stellenbosch has predefined templates for Microsoft Word that each student utilizes for their project, to adhere to a general style the university pursues. This has the benefit of having a consistent style along all published theses but dispossesses students of their own branding.
Innovation:
For todays standards this theme is not innovative anymore as game studios nowadays often hire renowned composers and orchestras for their music. However, before 2007-2010 (the thesis was published in 2010, but was started in 2007 or earlier) computer game companies were just beginning to do so. And as Pieter Crathorne himself wrote, earlier games just had programmers develop the music and not musicians compose the music. Of course, other resources already existed on music in computer games, but nothing had been going into as much detail as Crathorne did. And the main chapter, comparing games in genres and the genres themselves, had not been touched before at all.
Independence:
As this thesis does not have a project associated with it, it only consists of literary work. Thus, the author had to work on the thesis independently. Also, writing about the games’ music implicates having knowledge about the game, hence he independently played all of them as well.
Outline and Structure:
Pieter Crathorne developed a thought-through and understandable structure. While first giving a very basic overview of the theme and purpose of the study, he then starts with topics about music in general and steadily dives deeper into the computer game theme. Along the way, before the main analysis the author explains every bit of information, he will look at including differences between sound and music as well as defining genres as these often can be up to the listener’s (or in case of games the player’s) interpretation. The main section, analyzing all the games and their music, is divided into genres and sub-categorized into games, with comparisons in-between genres and with other genres in the “discussion” section. The conclusions are then summed up in the final chapter. The only issue I have with this thesis’ structure is the number of main chapters, which I believe could be reduced by combining some of the introductory chapters. Other than that, I was very pleased with the structure, so much so that I completely copied it and applied it to my own bachelor’s thesis.
Degree of Communication
Because Pieter Crathorne wrote a long and thorough introduction, I believe also people who are not directly from this scene understand most of his work. A background in gaming is not required at all, but I believe at least a little bit of knowledge about music might clarify parts of the thesis.
Scope of the Work
The thesis has 55 pages of actual content (= excluding front page, abstract, table of contents, bibliography and appendix). As there are no pictures in this thesis, I would categorize it as upper medium-sized. Because of the great explanations in the first few chapters, a shorter version would not have been possible and actually not been useful at all, as cutting content would just confuse the reader.
Orthography and Accuracy
In my opinion, Pieter Crathorne did a very good job keeping the thesis understandable and accurate. I did not notice any syntactic errors while reading through it (though I am not an expert, especially on commas) and all sentences were semantically coherent.
Literature
As this thesis is mostly about music in games, a big part of the literature is made up of video games. Crathorne cited 28 games in this thesis. That being said, there are 46 papers and articles listed in the bibliography, many of which come directly or indirectly from the game developers & publishers themselves. I do not know which citation style has been used, but all the citations follow the same style and include access dates wherever online media was used.
In this interesting article by Michel Chion [1] we can find the 3 main ways of listening.
What is a listening mode? Well, when we listen to some event we are likely to notice different things, and this changes from situation to situation. The way we perceive things at an exact moment is a way of listening. Even if the event is the same, the listening mode may be different because it depends on many other factors.
The first listening modality described in Chion’s article is causal listening.
This means listening to gather information about its cause.
This type of listening mode can be associated with multimodal perception, because we intend to try to discover the sound source thanks to our previous knowledge and current circumstances.
If the source is visible, the sound provides information about it, if it is not visible we would try to identify it with our knowledge or logical predictions, but out of context, it is difficult to clearly identify the source.
It is also associated with audio / video synchronization, which makes us believe that a certain sound is being produced by a certain source.
Even if we cannot identify the source of an event, for example a scraping noise, we are still able to follow is “evolution” = acceleration, slowdown… (changes in pressure, speed and amplitude).
The second is semantic listening, listening to interpret a language or a code.
It is a kind of linguistic listening, but it also applies to auditory icons and all other sounds that communicate a specific message.
This works in a complex way, as it is purely differential.
As mentioned in the text: “A phoneme is heard not strictly for its acoustic properties, but as part of a whole system of oppositions and differences. Thus, semantic listening ignores notable differences in pronunciation (and therefore in sound) if they are not differences pertinent to the language in question. Linguistic listening in both French and English, for example, is not sensitive to some very different pronunciations of the phoneme a”.
One listening mode does not exclude another. We can listen to a single event using, for example, causal and semantic modes at the same time.
The last is reduced listening, whose name is attributed to Pierre Schaeffer, French composer, engineer and writer, founder of the Groupe de Recherche de Musique Concrète (!).
This mode does not depend on the cause or meaning of the sounds, it just focuses on the traits themselves.
We can in some ways associate musical listening and analytical listening, even if more specific, because it tends to analyze only one characteristic of the sound (height, amplitude…).
You have to listen to the event many times to analyze all the characteristics of the sound, this means that the sound must be recorded.
For example, when we identify an interval between two notes (paying attention to the pitch) we are using reduce listening.
This mode has the advantage of “opening our ears and sharpening our listening skills”. The aesthetic value of sound is not only linked to its explanation, but also to its qualities, to its “personal vibration”.
Pierre Schaeffer thought that the acousmatic situation could favor this way of listening. The acousmatic situation is a situation in which the sound is heard without seeing the cause.
Yet the results of some tests have shown the opposite. The first thing we try to do is always try to understand the source of the sound and what that sound might be. It takes several plays of a single sound to allow us to gradually perceive its features without trying to understand the cause.
I would also like to mention a few other forms of listening that come to mind as I write this post.
The first is emotional / instinctive listening, which is not mentioned in Chion’s article, but is somehow associated with analytic listening, which brings us back to reduced listening. In reduced listening you should really focus on determining the sound traits, but in instinctive listening you can clearly and immediately understand the traits of sound that are important to you, due to the emotional characteristics, of course.
Then empathic listening, which applies when we listen to someone talking, and we try to understand their feeling and emotion.
I think our mindset also determines how we will understand information, plus if we are already prejudiced about what we will hear we would have some sort of selective listening. This is not good, because we will filter the information to reinforce our bias.
Titel Theoretische Planung und messtechnische Evaluierung eines Hallraumes
Hochschule Technische Universität Graz
Betreuer Dipl.-Ing. Herbert Hahn
Begutachter Ao. Univ.-Prof. Dipl.-Ing. Dr. Gerhard Graber
Autorin Jamilla Balint
Datum März 2014
Gestaltungshöhe Die Gestaltung dieser Diplomartbeit ist, wie bei vielen Arbeiten, die sich mit technischen Themen außeinandersetzen, eher schlicht und übersichtlich gehalten. Die Schriftart und die vielen Formeln deuten daraufhin, dass diese Arbeit mit LaTeX verfasst wurde.
Innovationsgrad Das Thema an sich ist nicht besonders innovativ, da sie zur täglichen Arbeit eines Akustikers zählt. Interessant ist allerdings der Aufwand der betrieben wurde, um verschiedene Messpositionen und Szenarien zu bewerten. Daraus ergeben sich Erkenntnisse, die man in der Realwirtschaft und in der praktischen Berufswelt nur schwierig bekommen würde.
Selbstständigkeit Die Autorin schreibt die Arbeit vollständig selbständig. Auch die praktischen Simulationen, Messungen und Auswertungen werden selbstständig erledigt. Lediglich der Hallraum wird von der TWB Buch GmbH zur Verfügung gestellt.
Gliederung und Struktur Die Gliederung und Struktur ist meiner Meinung nach gut gelungen und folgt einem logischen Aufbau. Zunächst werden die theoretischen physikalischen Grundlagen geklärt, dann wird die Software zur Simulation des Hallraumes vorgestellt. Anschließend folgt die praktische Simulation und die Messung mit einer Gegenüberstellung und Bewertung der Ergebnisse.
Kommunikationsgrad Die Thematik ist für einen Laien schwierig zu verstehen und geht tief in die Materie. Ohne physikalischen bzw. technischen Vorkenntnissen tut man sich schwer das Geschriebene außerhalb des Abstracts zu verstehen. Mit Vorkenntnissen hingegen lässt sich das Geschriebene gut nachvollziehen.
Umfang der Arbeit Die Arbeit ist mit einer Gesamtlänge von 113 Seiten eher lang, allerdings nehmen die physikalischen Formeln, Abbildungen und Tabellen auch viel Platz in Anspruch. Auch ist der Umfang angemessen für den praktischen Aufwand und die Komplexität des Themas
Orthographie sowie Sorgfalt und Genauigkeit Beim Lesen der Kapitel sind mir im groben keine grammatikalischen als auch orthographischen Fehler aufgefallen. Im Quellenverzeichnis sind mir allerdings Fehler wie “Sringer-Verlag Berlin” statt “Springer-Verlag Berlin” oder aber auch “Taschenbuch der Technichnischen Akustik” statt “Taschenbuch der Technischen Akustik” aufgefallen.
Literatur Die meiste Literatur basiert auf anerkannter Fachliteratur. Allerdings findet man auch einige Referenzen zu Studienarbeiten (Diplomarbeiten, Bachelorarbeiten) der TU Graz. Ob diese den wissenschaftlichen Standards entsprechen, um in einer Diplomarbeit zitiert zu werden ist, müsste überprüft werden. Da wissenschaftliche Quellen bei so speziellen Themen oft rar sind, wird die Autorin wohl aus diesem Grund aus anderen Studienarbeiten zitiert hat. Die Literatur, mit welcher die Autorin arbeitet, ist überwiegend aktuell, wobei auch einige ältere Werke aus den letzten Jahrzehnten vorkommen. Da ich selber Akustiker bin, kann ich aus eigener Erfahrung sagen, dass in der Akustik im Laufe der Zeit neue Erkenntnisse hinzukamen. Diese bauen aufeinaner auf, statt alte zu widerlegen, weshalb ältere Werke im wesentlichen nicht an Relevanz verloren haben.
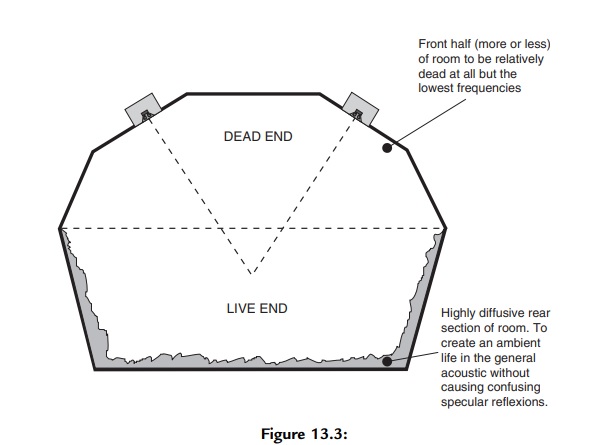
Im Bau und Konzeption von Regieräumen haben sich unterschiedliche Konzepte zum Umgang mit Reflexionen ausgehend von den Lautsprechern entwickelt. Besonders populär ist das sogenannte “Live-End, Dead-End“-Konzept (kurz LEDE). Dieses wurde Ende der 70er Jahre von Don und Carolyn Davis vorgestellt und in den darauffolgenden Jahren häufig umgesetzt. Aus eigener Erfahrung als Studioplaner kann ich sagen, dass Konzepte dieser Art ein wenig an Bedeutung verloren haben, weil Studios heutzutage eher funktional gebaut werden. Allerdings muss dazu gesagt werden, dass durch den massiven Rückgang der Verkäufe von Tonträgern auch die Budgets für teure Studiokonzepte und -umsetzungen fehlen.
Das LEDE-Konzept wurde unter der Beachtung psychoakustischer Effekte, wie dem Haas-Effekt und dem Richtungshören entwickelt. Dabei ist die Grundidee, dass der Regieraum in zwei Hälften geteilt wird. Der vordere Teil des Raums (Dead-End), wo sich auch die Lautsprecher befinden, ist komplett mit absorptivem Material verbaut, während die zweite Hälfte (Live-End), also die Rückwand und ein großer Teil der Seitenwände und Decke komplett reflektiv ist. Das Ziel ist es einen Direktschall zu erhalten, der sich hinsichtlich Prägnanz, Lautstärke und Zeit deutlich von den Erstreflexionen unterscheidet. Dazu wird die “Live-End”-Seite diffus gestaltet und der Schall so gestreut, dass man keine harten, diskreten Einzelreflexionen hat, welche den Klang zu sehr färben. Außerdem soll der Raum durch diese Maßnahme lebendiger und natürlicher klingen als typische Regieräume, die überwiegend mit Absorption bedämpft werden. Um dieses Konzept noch zu optimieren, werden die Lautsprecher in die Frontwand eingebaut, sodass die kugelförmige Abstrahlcharakteristik tiefer Frequenzen unterbunden wird. Damit bleibt der vordere Teil des Raumes komplett reflexionsfrei.
Tonregie mit sbsorptiver Front und reflektiver Rückseite
Es gibt aber auch den Ansatz Tonregien genau andersrum zu gestalten. In diesem Fall wird der vordere Bereich reflektiv gebaut und die Rückseite absorptiv. Dabei werden potentielle Erstreflexionen von der Rückwand und den Seitenwänden absorbiert.
Tonregie mit reflektiver Front und fest verbauten Lautsprechersystemen
Welches Konzept sinnvoller ist, ist in vielen Fällen eine Frage des Geschmacks und des gewünschten Höreindrucks. Erst durch das längerfristige Arbeiten in beiden Arten von Räumen kann ein eigenes Urteil gefällt werden.
Quellen:
Philip Newell. 2012. Recording Studio Design. Third Edition. S. 391 ff.
Um das Abklingverhalten eines Raumes zu beschreiben, wird der Begriff Nachhallzeit verwendet. Dieses bezeichnet die Zeit, in welcher ein Schallpegel um 60 dB abnimmt, nachdem die Schallquelle abgeschaltet wurde. Die Nachhallzeit ist dabei abhängig von der Raumgröße, der Raumgeometrie und der Oberflächenbeschaffenheit von Wänden, Böden und Decken. Nachhallzeiten verhalten sich im Frequenzspektrum nicht gleich, sondern unterscheiden sich, abhängig vom Oberflächenmaterial von Räumen, teilweise stark. Häufig brauchen tieffrequente Schallanteile länger um abzuklingen als hochfrequente.
Nachhallzeiten können zum einen gemessen, zum anderen aber auch berechnet bzw. simuliert werden, wenn die wesentlichen Variablen bekannt sind. Zur Berechnung der Nachhallzeit finden in der Praxis zwei Formeln Verwendung. Die Eyring’sche und die Sabine’sche Formel.
Für eine Nachhallzeitenkalkulation nach Eyring wird das Volumen des Raumes V und die gesamte Absorptionsoberfläche A benötigt. Letztere wird durch Addition der einzelnen Absorptionsoberflächen, die sich wiederum aus der Multiplikation der jeweiligen Absorptionsgrade α und der Oberflächengröße der unterschiedlichen Oberflächenmateriale ergibt, berechnet.
Berechnung der gesamten Absorptionsoberfläche
Daraus kann der mittlere Absorptionsgrad α des gesamten Raums berechnet werden. Dafür die gesamte Absorptionsfläche A mit der Gesamtoberfläche des Raumes Sges dividiert.
Berechnung des mittleren Absorptionsgrades
Mit diesen Variablen kann nun die Nachhallzeit nach Eyring berechnet werden. Hinzu kommt die Energiedämpfungskonstante. 4mV beschreibt die Absorption von Schall im Medium Luft. Bei kleinen Räumen und nicht zu hohen Frequenzen ist diese allerdings vernachlässigbar.
Berechnung der Nachhallzeit nach Eyring
Schwach bedämpfte Räume, also Räume mit einem mittleren Absorptionsgrad von α < 0,25 werden mit der vereinfachten Formel von Sabine berechnet.
Berechnung der Nachhallzeit nach Sabine
Die Nachhallzeit wird nun für jedes einzelne Frequenzband (in der Regel Terz- oder Oktavbänder) berechnet, um ein frequenzunabhängiges Verhalten der Nachhallzeit bestimmen zu können. Solche Kalkulationen werden vor allem bei der Planung von Gebäuden insbesondere von Konzerträumen, Tonstudios oder Konferenzräumen benötigt, um richtige Entscheidungen bezüglich der Innenausstattung und der Auskleidung von Oberflächen treffen zu können.
Title: Digital Simulation and Recreation of a Vacuum Tube Guitar Amp
Author: John Ragland
Academic degree: Degree of Master of Science
Place & date: Auburn, Alabama, May 2, 2020
I chose this work, because it could be a relevant thesis to the topic I might want to address in my Master thesis.
Level of design
The design level of this work is quite good. The lists and the standardization of the structure make the work really easy to read and understand.
Degree of innovation
While it’s a pretty cool theme, it’s not that innovative. It is a field that has been studied before, and although the model he has chosen to recreate is quite interesting, it has already been done. However, the results are positive and important for this field.
Independence
It is not so easy to assess its independence. Since it is only practical / technical work and the author had to do everything himself (and of course with the help and suggestion of the tutors) I would say that he is quite independent.
Outline and structure
This work is well structured, everything is clear and it is easy to scroll through the pages. There is just a bit of confusion in the structure of the index, where sometimes the chapters are written not in the right chronological order, and this bothers me a little.
Degree of communication
It is really clear. The list of abbreviations at the beginning of the work makes everything immediately clear. Explaining all the terms in the beginning helps a lot to avoid wasting time looking for them somewhere in the text.
I think that even those who are not an expert could follow this work and understand it (even if not 100%, due to a technical / specific mathematical procedure). The support of images and diagrams helps a lot to visualize the whole process.
Scope of the work
The work is about 48 pages. I would consider it a bit too short for a master thesis. The process is really well explained, but perhaps some theoretical themes or previous work could have been described in more depth.
Orthography and accuracy
Except for some space or quotation mark errors, there are no grammatical errors. The sentence structure is also well done.
Literature
I would say there is a good amount of literature. Most of them are not online sources and all are specialist publications.
This article talks about some of the Sound Art projects/installations that serve as an essential guide to the art of sound design. The list contains diverse types of works featuring interesting perspective and a different approach to sound.
Luigi Russolo, Gran Concerto Futuristico (1917)
Luigi Russolo (1885 – 1947) the futurist artist with his assistant Piatti and the noise machine invented by him for futurist ‘symphonies’, one of which was performed at the London Coliseum in June 1914. (Photo by Hulton Archive/Getty Images)
Luigi Russolo is perhaps best known as a painter associated with the Futurist movement in Italy. However, he is also considered one of the earliest (maybe even first) experimental noise painters. Inspired by World War I factory equipment and guns, he invented and built an acoustic noise generator called Intonarumori (meaning “noise source” in Italian). In 1913 he published the Art of Noises, in which he argued that the evolution of urban industrial soundscapes required a new approach to music. For Russolo, melodic music limited the human potential for appreciating more complex sounds. In 1917 he attempted to correct this in his play Gran Concerto Futuristico, for which he put together a noise orchestra playing offending sounds (Music did not sound classical.) Despite the widespread criticism he faced in connection with this piece, he continued to perform well after World War I. Today, his manifesto is considered one of the most important texts in 20th-century music theory.
Marcel Duchamp, Erratum Musical (1913)
50 Years Ago Today, Marcel Duchamp and John Cage Played Chess. Photo: Shigeko Kubota, courtesy the John Cage Trust
Marcel Duchamp was fascinated by how he was able to visualise sound. He said: “You can’t hear the gossip.” Despite being untrained, he was composing music between 1912 and 1915. The end result was radically different from the off-the-shelf Dada model that made him famous. He developed one purely conceptual piece and two conceptual exercises to play, including the Erratum Musical, a randomly arranged sheet music composed for three voices. Duchamp created three sets of 25 cards. F (from F below middle C to F high) with 1 entry per card. Cards are shuffled in the hat and then drawn one at a time. Then I wrote a series of notes in the order in which I removed the cards from the hat. Performers can decide how they want to perform their piece. Duchamp did not give a score in this regard.
John Cage, 4’33” (1952)
John Cage performing his silent piece at the Maverick hall. Courtesy of Getty Images
For his masterpiece, Cage explored the potential of silence, revolutionising sound art and performance. He is best known for his composition of 4:33 seconds, a three-part composition of 4:33 seconds of silence. Inspired by a visit to the anechoic chamber at Harvard University, the work is not known to contain anything special. The performer is invited not to play the instrument or make any noise. However, no silence is truly silent, and the audience is keenly aware of the sounds of the environment during pauses. This koan-like paradox was based on what Cage heard in a Harvard auditorium. He discovered that he could hear his own heartbeat. He wrote of the experience, “I will hear it until I die.” “And they will continue after I die. You don’t have to be afraid of the future of music.”
Bill Fontana, Distant Trains (1984)
Fontana prepairing and installing his public piece
By the 1960s and early 1970s, advances in digital media increased the opportunities of visible artists and composers running on the intersection of sound and sculpture. Bill Fontana become a pioneer in growing sculpted sound maps for city environments. At the “Remote Trains” exhibition in Berlin for a month in 1984, a loudspeaker become buried withinside the web website online of the previous Anhalter Bahnhof Station, one in every of Europe’s busiest teach stations earlier than World War II. It become destroyed with the aid of using bombing at some stage in the conflict and become formally decommissioned in 1952. A stay microphone become housed withinside the Köln Hauptbahnhof, which recreates the phantom sound surroundings with the aid of using transmitting acoustics in actual time from the noisy station to the deserted Anhalter Bahnhof.
Max Neuhaus,Times Square (1977–92)
Neuhaus’ work constantly playing from a Manhattan subway steam hatch
Max Neuhaus’s most famous work is a pulsating drone that fires 24 hours a day, 7 days a week from a subway steam hatch at the northern tip of Manhattan’s triangular pedestrian island. (Thanks to the MTA and the Dia Art Foundation, this work is permanent near Times Square.) Inside it, the pitch and pitch change as passers-by move around the block. “A rich harmonic sound texture reminiscent of a large bell after a bell is ringing is impossible in this context,” Neuhaus said. “For those who discover and embrace the impossibility of sound, the island becomes another place that includes its surroundings but is separate.”
Carsten Nicolai,Reflektor Distortion(2016)
Excerpt from Nikolai’s visible sound installation. Photo courtesy of Zhi Art Muesum
Berlin and Chemnitz artist Karsten Nikolai has been working since the 1980s at the intersection of sound media, science and the visual arts. Nikolai, co-founder of the influential “sound not sound” electronic music label RasterNoton, has exhibited sound and video installations twice: at Documenta X in Kassel, Germany and at the Venice Biennale, Italy. Much of his work is aimed at creating sound and light phenomena perceived by the human eye and ear. In 2016 he presented the Reflektor Distortion at Galerie Eigen + Art Berlin, where a rotating water bass strikes through a speaker at a low audible frequency. The ripples in the water reflected the frequency of the waves, making the sound visible only for a short period of time.
Jem Finer, Longplayer (1999)
First live performance on the Longplayer at the Trinity Buoy Wharf, where it is stationed. 2009
On December 31, 1999, the British musician and artist Jem Finer began playing a piece of ambient music that will finish in the year 3000. Provided humanity endures another 1,000 years, Longplayer will be the most epic piece of music ever performed, outstripping John Cage’s 639-year-long organ concert currently taking place in a church in Halberstadt, Germany. Longplayer is housed in a lighthouse in London and processed by a computer algorithm that mechanically extends the sound of a single instrument consisting of 234 Tibetan singing bowls. The sound is without repetition or break. “The intention [of Longplayer] is that its droning and parping will, like this year’s eclipse, make the hearers ponder the passing of time in a way that makes you feel both mortal and insignificant,” wrote the Evening Standard on the night of its commencement in 1999.
Christian Marclay, Recycled Records(1980–86)
Marclay created new pieces by combining parts of different vinyl records. Photo courtesy of Paula Cooper Gallery, New York
For nearly 40 years, Swiss-American sound artist and experimental DJ Christian Marclay has manipulated sound into physical form through photography, sculpture, installation, and performance. The artist is credited with pioneering an experimental form of turntablism, in which sound is altered through multiple turntables. Inspired by the noise experiments of composer John Cage and early hip-hop DJs, Marclay began incorporating prerecorded dissonant sounds produced by vinyl records in motion into his turntable performances. In the seminal series “Recycled Records,” the artists sliced apart vinyl records and reassembled the pieces to create new arrangements.
Susan Philipsz, Lowlands(2010)
Turner Prize.Artist Susan Philipsz inside her sound installation ‘Lowlands’, after being named as the winner of the Turner Prize 2010, at Tate Britain, in central London. Picture date: Monday December 6, 2010. See PA story ARTS Turner Philipsz. Photo credit: Dominic Lipinski (Press Association via AP Images)
The Scottish-born, Berlin-based artist Susan Philipsz uses site-specific sound installations to probe the link between sense and memory. “Sound is materially invisible but very visceral and emotive,” she once said. “It can define a space at the same time as it triggers a memory.” In 2010, she was awarded the Turner Prize for the sound installation Lowlands, the first work of its kind ever to earn an artist the famed award. In the winning iteration of the piece, Philipsz performed three variations of a Scottish lament about a drowned lover who returns to her lover’s dreams, beneath three bridges over the River Clyde during the Glasgow International Festival of Visual Art. The Turner judges also considered Long Gone, in which a recording of the artists singing the eponymous Syd Barrett song played at the entrance of the Museo de Arte Contemporánea de Vigo in Spain. Her win attracted criticisms from detractors who argued that she should be classified as a singer, not an artist. The judges, however, insisted otherwise.
Samson Young, For Whom the Bell Tolls: A Journey Into the Sonic History of Conflict (2015)
Young on his journey across 5 continents , recording historically significant bells
A traditionally trained composer, Hong-Kong based Young has been on the rise since he won the inaugural edition of Art Basel’s BMW Art Journey Award in 2015 for his project For Whom the Bell Tolls: A Journey Into the Sonic History of Conflict. Over two-months, he documented the chime of iconic bells across five continents. He then crafted responses which explored the bells’ status as musical instruments and political, social, and religious representations of their communities. In June 2016, he drew critical acclaim at Art Basel Unlimited for a similar exploration into the militarization of sound. Seated atop a booth-sized cube and dressed in police uniform, Young performed with a Long Range Acoustic Device, a sonic weapon used to disperse crowds at protests. A low level form of the weapon is also used to repel birds from private properties, which Young represented by recreating distressed bird calls.
Christine Sun Kim, Close Readings (2015)
Exceprt from the collection of captions Sun Kim collected from her deaf friends
Berlin-based artist Christine Sun Kim centers the systemic barriers attached to deafness. Kim was selected for the 2013 MoMA exhibition “Soundings,” the museum’s first major show dedicated to sound art. In 2019, a group of charcoal drawings by Kim were included in the Whitney Biennial. The work, along with the piece One Week of Lullabies for Roux (2018), became the first sound art installations acquired by the Smithsonian American Art Museum in 2020.
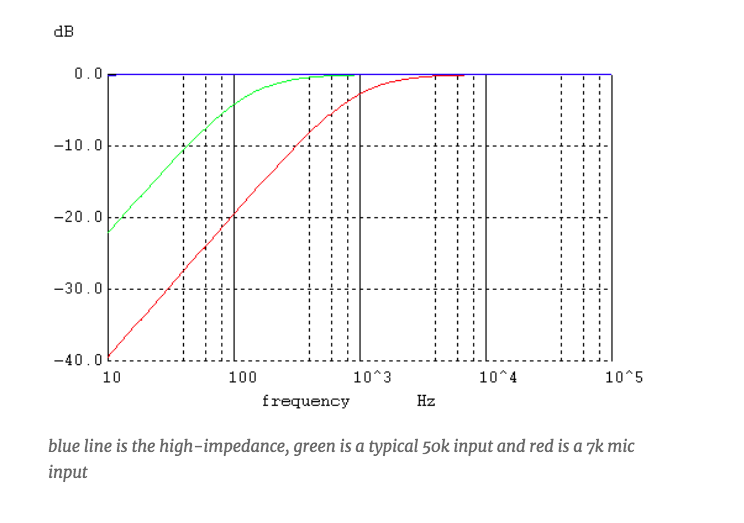
Piezo microphones are also called contact microphones, this means that they are attached to a surface and can perceive audio vibrations through it. They are not sensitive to air vibrations, but only transduce the sound transmitted by the structure.
They have many applications, they are used to detecting drums hits, to trigger electronic samples or even underwater. For these applications they work fine.
They are often used to amplify acoustic musical instruments, and this is where the problems begin.
Contact microphones are not well-matched to typical audio inputs. They cannot drive a 50 kilohm input, which is the typical line input.
Most Piezos are tuned speaker elements used in reverse, the microphone is glued to a brass disc designed to resonate between 2-4kHz so that with a small power input you get a great audio output.
The problem is that they are often paired with a standard audio load, which normally loses low frequencies.
The Piezo sensor presents its signal through a series capacitance of approximately 15nF. When connected to a regular 50 kilohm line input, this forms a 200 Hz high pass filter, so here’s the main problem!
And, when connected to a consumer plug-in microphone input with an impedance of about 7 kilohms, the result is a 1kHz high-pass filter.
This should be inserted into a load that is higher than the impedance of the series capacitor at the lowest frequency of interest. If this is 20Hz, since the capacitor impedance is 1 / 2pifreq * C, then it should be above 530k.
This means that a high impedance input gets the blue line in the graph above.
Maybe you might think about EQing it later, but you will also start increasing the noise and hum at low frequencies.