
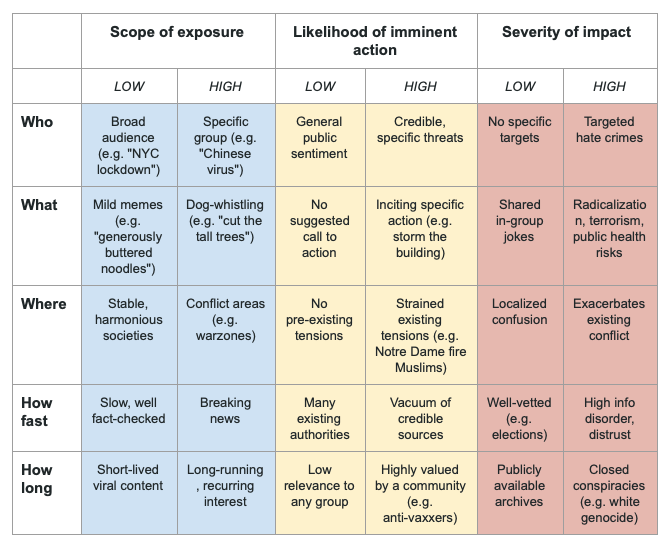
“Data voids are a security vulnerability that must be systematically, intentionally, and thoughtfully managed.”
When talking about data voids, people often forget that there are different kind of information and most importantly the process of getting information. Search engines, for example, use another strategy compared to social media platforms. Search engines like Google or similar have lots and lots of data, but people’s approaches to search engines typically begin with a query or question in an effort to seek new information. However, not all search queries are equal. So, if you’re searching for a term like “ironing”, you’ll most certainly get some adds and some organically produced output (SEO), but nothing about “extrem ironing” (although it is quite fun to look at these pictures). In comparison to that social media, where users primarily consume an algorithmically curated feed of information. When there is not enough, too little or no data at all about a certain topic it is called a data void. When search engines have little natural content to return for a particular query, they are more likely to return low quality and problematic content. As already mentioned before, bad or low quality content ist harmful to our society.
According to datasociety.net there are five types of data voids in play:
- Breaking News: The production of problematic content can be optimized to terms that are suddenly spiking due to a breaking news situation; these voids will eventually be filled by legitimate news content, but are abused before such content exists.
- Strategic New Terms: Manipulators create new terms and build a strategically optimized information ecosystem around them before amplifying those terms into the mainstream, often through news media, in order to introduce newcomers to problematic content and frames.
- Outdated Terms: When terms go out of date, content creators stop producing content associated with these terms long before searchers stop seeking out content. This creates an opening for manipulators to produce content that exploits search engines’ dependence on freshness.
- Fragmented Concepts: By breaking connections between related ideas, and creating distinct clusters of information that refer to different political frames, manipulators can segment searchers into different information worlds.
- Problematic Queries: Search results for disturbing or fraught terms that have historically returned problematic results continue to do so, unless high quality content is introduced to contextualize or outrank such problematic content.
So how can we fill these voids with qualitativ data?
The biggest problem with these newly occurring data voids is the enormous speed in which they are spread and some of them are spread through apps like WhatsApp or Telegram. So the main problem is how can we know if there is a data void in development. In the following video it is explained why fast response to search engines most searched questions with fact checking is so important.
At the end of this research post the most important question for me is how can we filter and label all of this content properly and fast enough to not let these kinds of data voids arise.
One and in my personal opinion the most promising solution could be a browser based plugin which would have to be operated by an independent platform fo experts. This platform must have its own funding so that there can be no rumors of corruption, propaganda and so on. This means it could be like an individually paid virus detection software, but for detecting false information, filtering and labelling it and also filling data voids as soon as they arise.
Links:
https://medium.com/@Assembly_Program/into-the-voids-exploring-data-voids-af101e228784
https://datasociety.net/wp-content/uploads/2018/05/Data_Society_Data_Voids_Final_3.pdf