This is an introduction to fact-checking sites and a clear definition of false information streams.
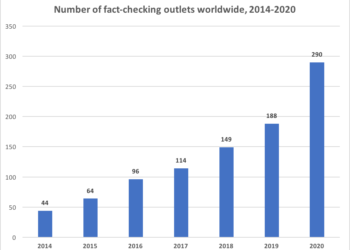
From politicians to marketers, from advocacy groups to brands — everyone who seeks to convince others has an incentive to distort, exaggerate or obfuscate the facts. This is why fact-checking has grown in relevance and has spread around the world in the recent decade.
According to a paper by Alexios Mantzarlis “MODULE 5 – Fact-checking 101” the type of fact-checking happens not before something is published but after a claim becomes of public relevance. This form of “ex post” fact-checking seeks to make politicians and other public figures accountable for the truthfulness of their statements. Fact-checkers in this line of work seek primary and reputable sources that can confirm or negate claims made to the public.
Alexios Mantzarlis also wrote about two moments, which were particularly significant to the growth of this journalistic practice. A first wave was kick-started by the 2009 Pulitzer Prize for national reporting, assigned to PolitiFact, a fact-checking project launched just over a year earlier by the St Petersburg Times (now Tampa Bay Times) in Florida. PolitiFact’s innovation was to rate claims on a “Truth-O-Meter”, adding a layer of structure and clarity to the fact checks.
Truth-O-Meter by PolitiFact
The second wave of fact-checking projects emerged following the global surge in so-called ‘fake news’. The term, now co-opted and misused, describes entirely fabricated sensationalist stories that reach enormous audiences by using social media algorithms to their advantage.
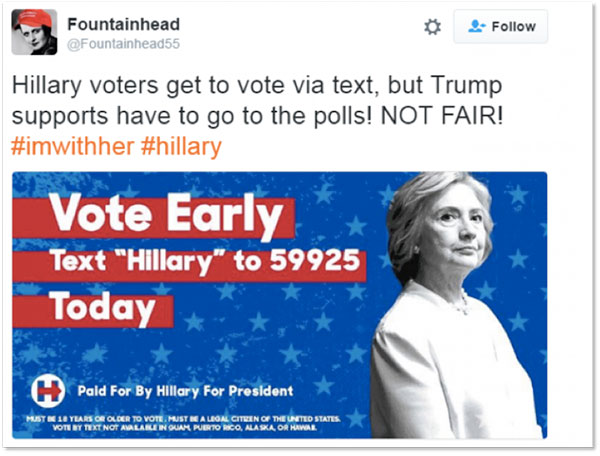
Vote Early False Information
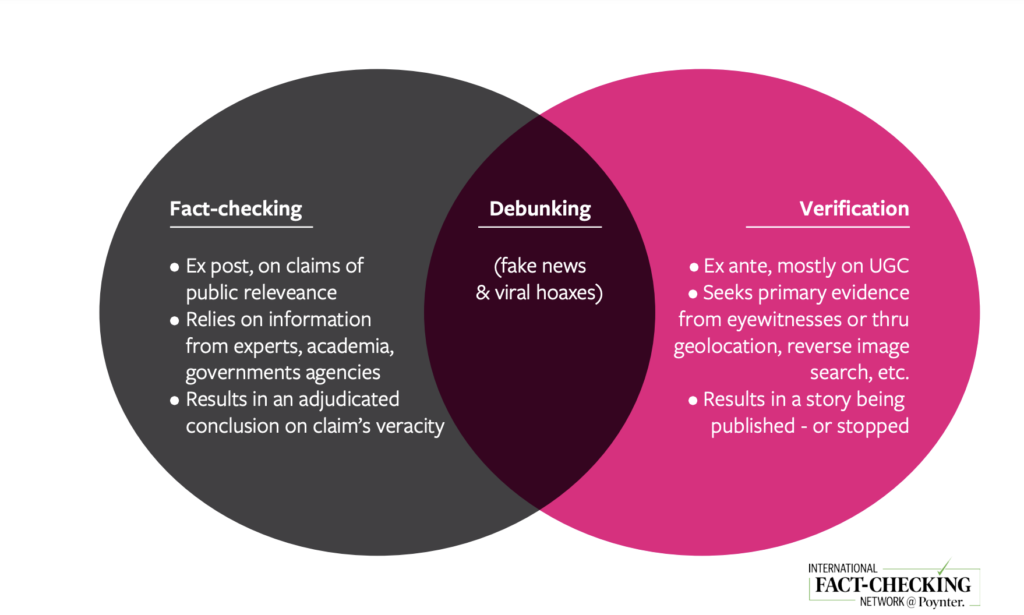
This second wave often concentrated as much on fact-checking public claims as debunking these viral hoaxes. Debunking is a subset of fact-checking and requires a specific set of skills that are in common with verification.
The difference between Fact-checking and Verification
In part two an analysis and comparison of cloaked websites, which are sites published by individuals or groups who conceal authorship in order to disguise deliberately a hidden political agenda, and fact-checking sites will be done. Therefore the websites will be compared on the basis of the following factors:
User Experience (Survey about fact checking websites credibility)
As mentioned in recent posts there are multiple reasons for the rise and existence of false or misleading information in the digital age. Some of them occur because of a data void, but there are also other reasons like the so-called filter bubbles, where an algorithm selectively guesses what information a user would like to see based on information about the user, such as location, past click-behavior and search history. This term was coined by internet activist Eli Pariser in 2010 and also discussed in his 2011 book of the same name. As a result, users get isolated from information that might differ from their own opinion. This leads to less discourse of information and again might be harmful for our civic discourse.
The extrem negativ effects a filter bubble can have is shown in the following video THE MISEDUCATION OF DYLANN ROOF (Trigger warning: Violence, Racism and racial slurs, Hateful language directed at religious groups).
Here is a short video of things to look for when you are uncertain or just want to know what to look for when surfing the world wide web:
Spotting Bogus Claims
Despite the things to look for mentioned in the video, sometimes that is not enough. If you watched the video about the miseducation of dylann roof, you will clearly realize that websites which spread false information or hate speech are sometimes designed in a similar way to other reliable news pages, which can make it difficult for not savvy users to identify propaganda and misinformation.
Since 2010 a lot of fact checking sites appeared. Most of them rely on the same principle. They use donations to do their work and they write articles about current rumors.
FactCheck.org
Fact checking sites like FactCheck.org or the The Washingtion Post Fact Checker like to comment on mostly false information spread by politicians and such. However, they do not show or label content compared to the social media platforms, on which false information is spread throughout the platforms and also shared to other social interaction platforms. You will find statistics about that here.
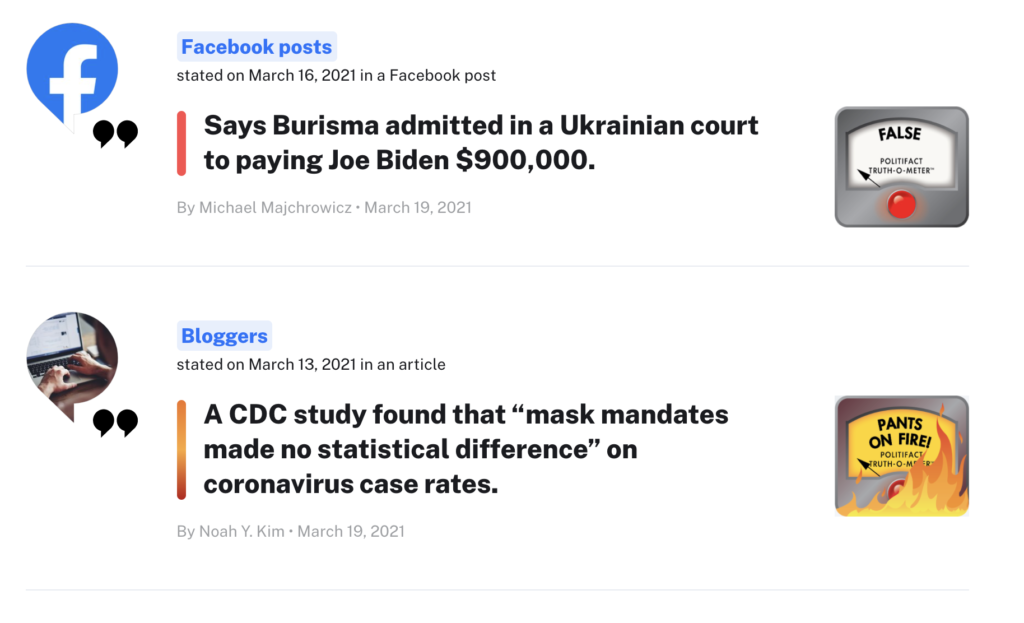
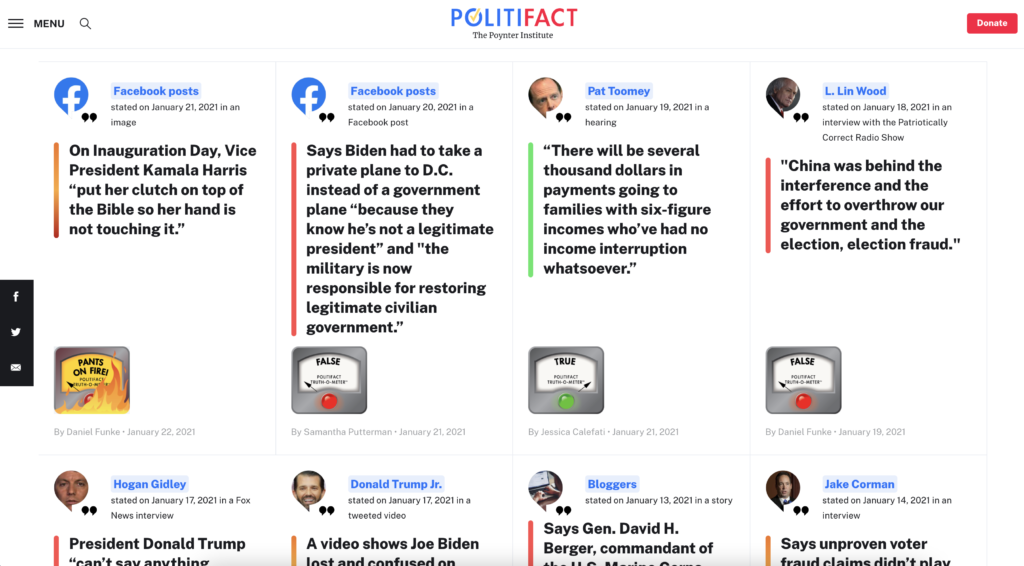
Other sites like PolitiFact show statements and their truthfulness in form of an “Truth-O-Meter”. In my personal opinion the design of the quotes and the “Truth-O-Meter” does not look really sophisticated and believable. In the next post I want to do a survey about the credibility of these sites and their designs.
PolitiFact
Another fact checking organization or institute is IFCN. This website is really transparent and well designed. Its function is described as follows: “The code of principles of the International Fact-Checking Network at Poynter is a series of commitments organizations abide by to promote excellence in fact-checking. We believe nonpartisan and transparent fact-checking can be a powerful instrument of accountability journalism.”
ifcncodeofprinciples.poynter.org
They use a clear and consistent design language, like corporate colors and fonts. The International Fact-Checking Network is a unit of the Poynter Institute dedicated to bringing together fact-checkers worldwide. Also they use a corporate badge to verify organizations, which looks like this:
IFCN Badge
Around 100 fact checking or news organizations all over the world use this service or way of validating, even tough it is not an easy application process. Next to other reasons why implementing such a verification is important, the good design is clearly making the site more sophisticated.
“Data voids are a security vulnerability that must be systematically, intentionally, and thoughtfully managed.”
When talking about data voids, people often forget that there are different kind of information and most importantly the process of getting information. Search engines, for example, use another strategy compared to social media platforms. Search engines like Google or similar have lots and lots of data, but people’s approaches to search engines typically begin with a query or question in an effort to seek new information. However, not all search queries are equal. So, if you’re searching for a term like “ironing”, you’ll most certainly get some adds and some organically produced output (SEO), but nothing about “extrem ironing” (although it is quite fun to look at these pictures). In comparison to that social media, where users primarily consume an algorithmically curated feed of information. When there is not enough, too little or no data at all about a certain topic it is called a data void. When search engines have little natural content to return for a particular query, they are more likely to return low quality and problematic content. As already mentioned before, bad or low quality content ist harmful to our society.
According to datasociety.net there are five types of data voids in play:
Breaking News: The production of problematic content can be optimized to terms that are suddenly spiking due to a breaking news situation; these voids will eventually be filled by legitimate news content, but are abused before such content exists.
Strategic New Terms: Manipulators create new terms and build a strategically optimized information ecosystem around them before amplifying those terms into the mainstream, often through news media, in order to introduce newcomers to problematic content and frames.
Outdated Terms: When terms go out of date, content creators stop producing content associated with these terms long before searchers stop seeking out content. This creates an opening for manipulators to produce content that exploits search engines’ dependence on freshness.
Fragmented Concepts: By breaking connections between related ideas, and creating distinct clusters of information that refer to different political frames, manipulators can segment searchers into different information worlds.
Problematic Queries: Search results for disturbing or fraught terms that have historically returned problematic results continue to do so, unless high quality content is introduced to contextualize or outrank such problematic content.
So how can we fill these voids with qualitativ data?
The biggest problem with these newly occurring data voids is the enormous speed in which they are spread and some of them are spread through apps like WhatsApp or Telegram. So the main problem is how can we know if there is a data void in development. In the following video it is explained why fast response to search engines most searched questions with fact checking is so important.
At the end of this research post the most important question for me is how can we filter and label all of this content properly and fast enough to not let these kinds of data voids arise.
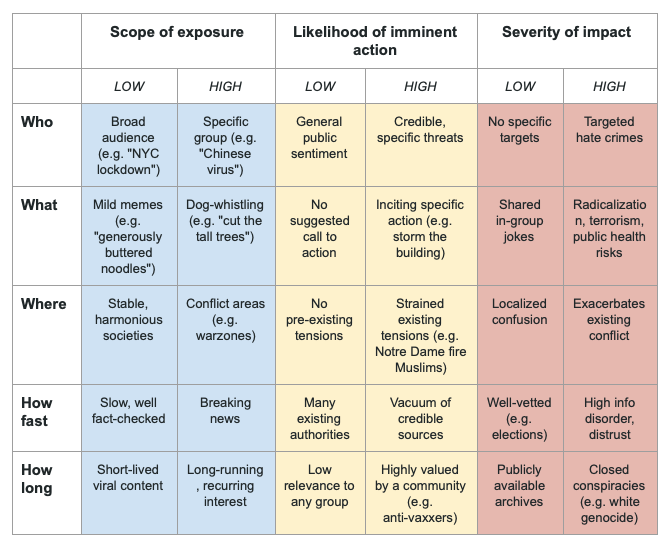
Harms framework to explore the risks posed by data voids
One and in my personal opinion the most promising solution could be a browser based plugin which would have to be operated by an independent platform fo experts. This platform must have its own funding so that there can be no rumors of corruption, propaganda and so on. This means it could be like an individually paid virus detection software, but for detecting false information, filtering and labelling it and also filling data voids as soon as they arise.
In times of new media and fake news it is hard to know which facts are actually true and which are not but why is this a problem for humanity?
You might think that some misinformation might not be harmful, but a workshop of Yale Law School and the Floyd Abrams Institute for Freedom of Expression showed that fake news can have a bad influence on our society. This problem exists not only in politics but also in our daily life. But what means bad influence and how can we make the online world more transparent?
Since the beginning of time humans were never exposed to such tons of data as we know today. At the beginning of the internet age people did not really use or understand the power of the world wide web. It started around the turn of the century that humans got connected and since then it increased exponentially. The devices got easier to use and the screen design improved as well. Originally most of the information online was reduced to fun articles and some early staged websites with mostly bad usability but that changed quickly. More and more humans became as we call them “Users” and at the same time the amount of misinformation rose and the transparency decreased. Nowadays it is hard to distinguish what information is correct and what is only there to get our emotions out of control. Bots and people who distribute false stories for profit or engage in ideological propaganda are now part of our everyday life as we spend around up to seven hours a day in front of a screen. Since the beginning of the pandemic our daily screen time might have increased even more. The positive or negative health effects of screen time are influenced by quality and content of exposure. The most salient danger associated with “fake news” is the fact that it devalues and delegitimizes voices of expertise, authoritative institutions, and the concept of objective data – all of which undermines society’s ability to engage in rational discourse based upon shared facts.
Reseach result of the American Press Institute
In 2014 some researches tried to cluster algorithms which have emerged as a powerful meta-learning tool to analyze massive volumes of data generated by time-based media. They developed a categorizing framework and highlighted the set of clustering algorithms which were best performing for big data. However, one of their major issues was that it caused confusion amongst practitioners because of the lack of consensus in the definition of their properties as well as a lack of formal categorization. Clustering data is the first step for finding patterns which may lead us to detecting misinformation, false stories, ideological propaganda or so-called fake news. It is also a method for unsupervised learning. Furthermore, it is a common technique for statistical data analysis used in many other fields of science and if used correctly it could be a game changer for our online and offline society.
PEW Research Center Internet and Technology
Why does Fake News exist?
A pretty important thing to know about social media, is that always the most recent published or shared content is the first you will see. That means if there is no reliable recent post on a topic, it leaves a so-called data void behind, which means as soon as somebody publishes something new on this topic, it will be shown first. This comes from the fact that we always long for “new” news, despite the fact that no one, no tool nor algorithm has ever screened these information verifying its accuracy.
Example of how data voids work
What about Twitter?
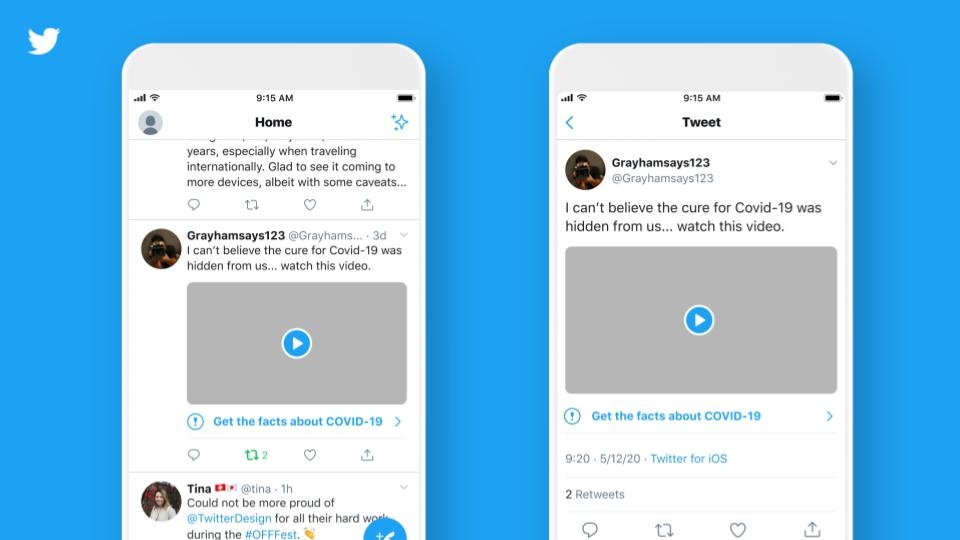
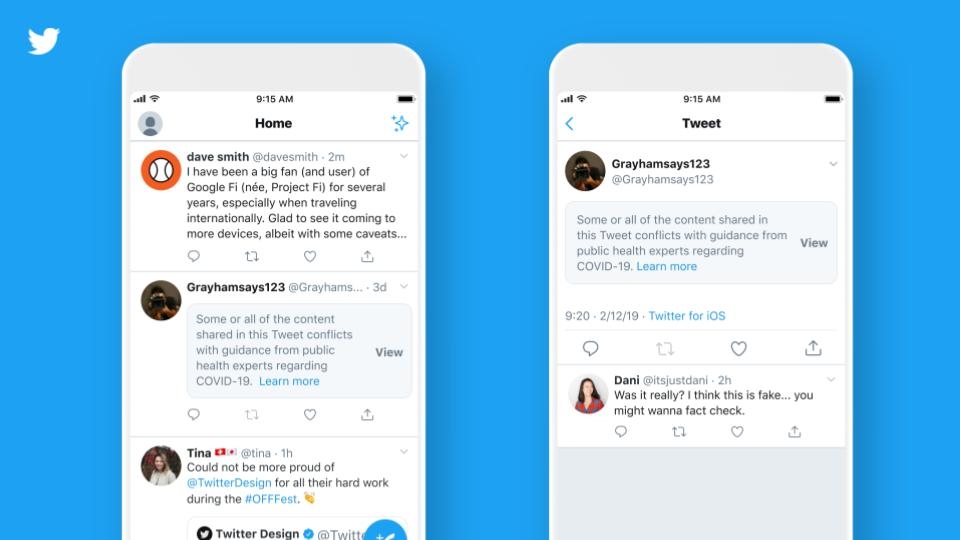
Since May 2020 Twitter is trying to make it easy or easier to find credible information and to limit the spread of potentially harmful and misleading content. They introduced new labels and warning messages that will provide additional context and information on some Tweets. These labels will link to a Twitter-curated page or external trusted sources containing additional information on the claims made within the Tweet.
Twitter labels for false information about COVID-19Twitter warnings for conflicting content
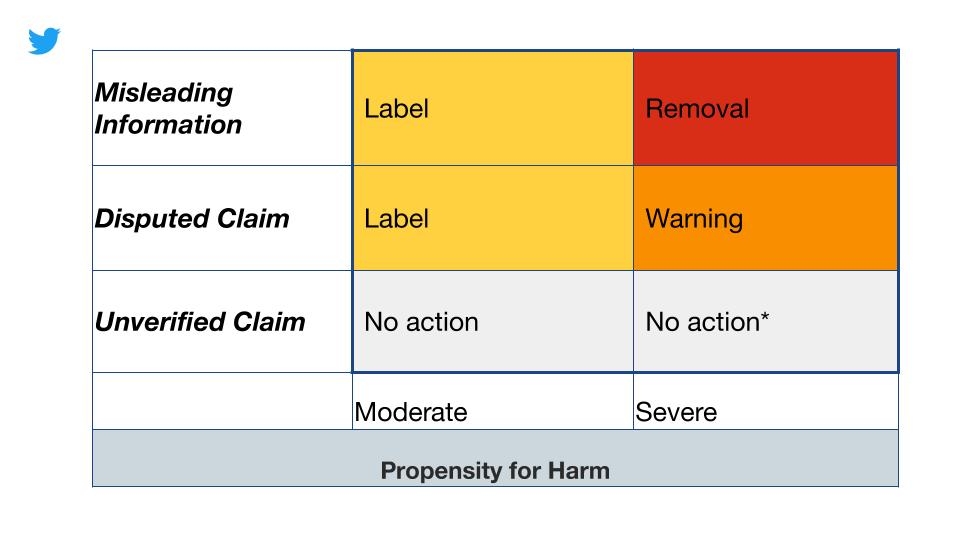
So Twitter is one of the major social media platforms actually labeling content, despite it being the Tweet of the current president of America alias Donald J. Trump. Also they are actively trying to decrease the spread of misinformation though introducing an extra notice before you can share conflicting content. Since content can take many different forms, they started clustering the false or misleading content into three broad categories:
categories of false or misleading content
Of course Twitter is not the only platform labeling false information or content going viral – Facebook and Instagram started doing that too. Instagram has been working with third-party fact checkers, but up until now the service was far less aggressive with misinformation than Facebook. Also qualitativ fact checking takes time, which can be problematic and there is still some catching up to do.
Facebook and Instagram – labeled content
Labeling or removing postings is a first approach in the right direction, but it does not solve all issues that come with false information and how we interact with it. This is why this topic is so important for the future and the wellbeing of our society.
Sources:
Fighting Fake News Workshop Report hosted by The Information Society Project & The Floyd Abrams Institute for Freedom of Expression