Part 1: What is Machine Learning?
Machine Learning is essentially just a type of algorithm that improves over time. But instead of humans adjusting the algorithm the computer does it itself. In this process, computers discover how to do something without being programmed to do so. The benefits of such an approach to problem solving is that algorithms too complex for humans to develop can be learned by the machine. This leads to programmers being able to focus on what goes in to and what out of the algorithm rather than the algorithm itself.
Approaches
There are three broad categories of machine learning approaches:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised learning is used for figuring out how to get from an input to an output. Inputs are classified meaning the dataset (or rather trainset, the part of the dataset used for training) is already split up into categories. The goal of using supervised learning is to generate a model that can map inputs to outputs. An example would be automatic audio file tagging – like either drum or guitar.
Unsupervised learning is used when the input data has not been labelled. The algorithm has to find out on its own how to describe a dataset. Common use cases are feature learning and discovering patterns in data (which might not have been visible without machine learning).
Reinforcement learning is probably what you have seen on YouTube. These are the algorithms that interact with something (like a human would do with a controller for example) and is either punished or rewarded for its behavior. Algorithms learning to play Super Mario World or Tesla’s Autopilot are trained with reinforcement learning.
Of course, there are other approaches as well, but these are a minority, and it is easier to just stick with the three categories above.
Models
The process of machine learning is to create an algorithm which can describe a set of data. This algorithm is called a model. A model exists from the beginning on and is trained. Trained models can then be used for example to categorize files. There are various approaches to machine learning:
- Classifying
- Regression
- Clustering
- Dimensionality reduction
- Neural networks / deep learning
Classifying models are used to (you guessed it) classify data. They predict the type of data which can be several options (for example colors). One of the simplest classifying models is a decision tree which follows a flowchart-like concept of asking a question and getting either yes or no as an answer (or in more of a programmer’s terms: if and else statements). If you think of it as a tree (the way it is meant to be understood) you start at the root with one question, then get on to a branch where the next question is until you reach a leaf, which represents the class or tag you want to assign.

Regression models come from statistical analysis. There are a multitude of regression models, the easiest of which is the linear regression. Linear regression tires to describe a dataset with just one liner function. The data is mapped on to a 2-dimensional space and then a linear function which “kind of” fits all the data is drawn. An example for regression analysis would be Microsoft Excel’s trendline tool.

Clustering is used to group similar objects together. If you have unclassified data and want to make use of supervised learning, regression models can automatically classify the objects for you.
Dimensionality reduction models (again an aptronym) reduce dimensionality of the dataset. The dimensionality is the number of variables used to describe a dataset. As usually different variables do not contribute equally to the dataset, the dataset can still be reliably described by less variables. One example for dimensionality reduction is the principal component analysis. In 2D space the PCA generates a best fitting line, which is usually where the least squared distance from the points to the line is.
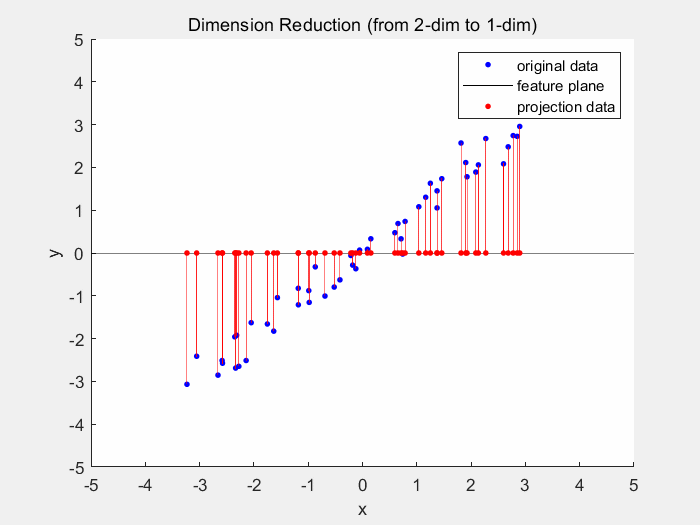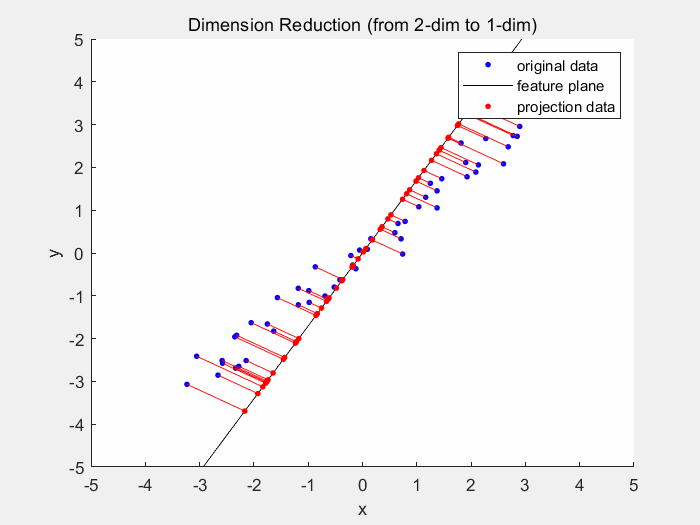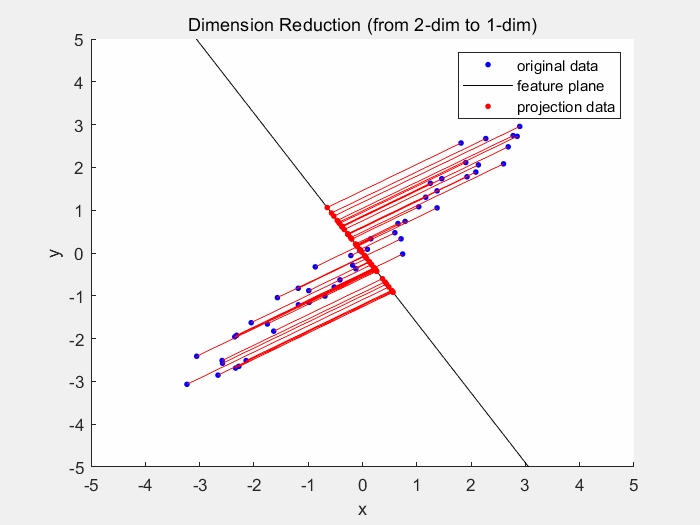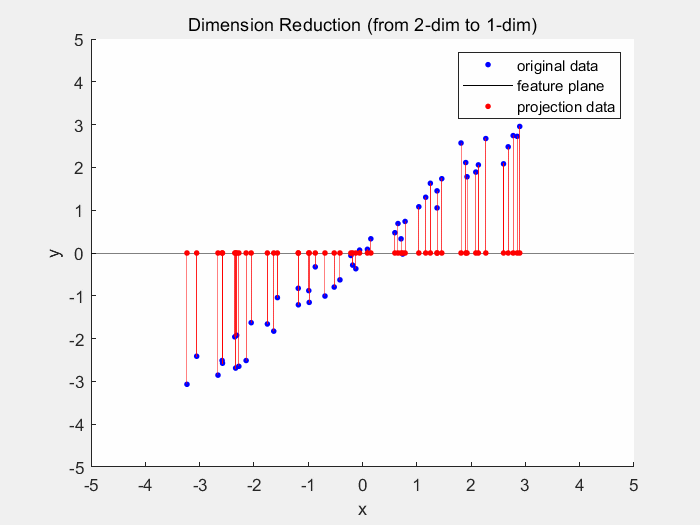
Deep Learning will be covered in part 2 of this series as this is the main focus of this series.
Read more:
https://en.wikipedia.org/wiki/Glossary_of_artificial_intelligence
https://www.educba.com/machine-learning-models/
https://www.educba.com/machine-learning-algorithms/