Convolutional Networks
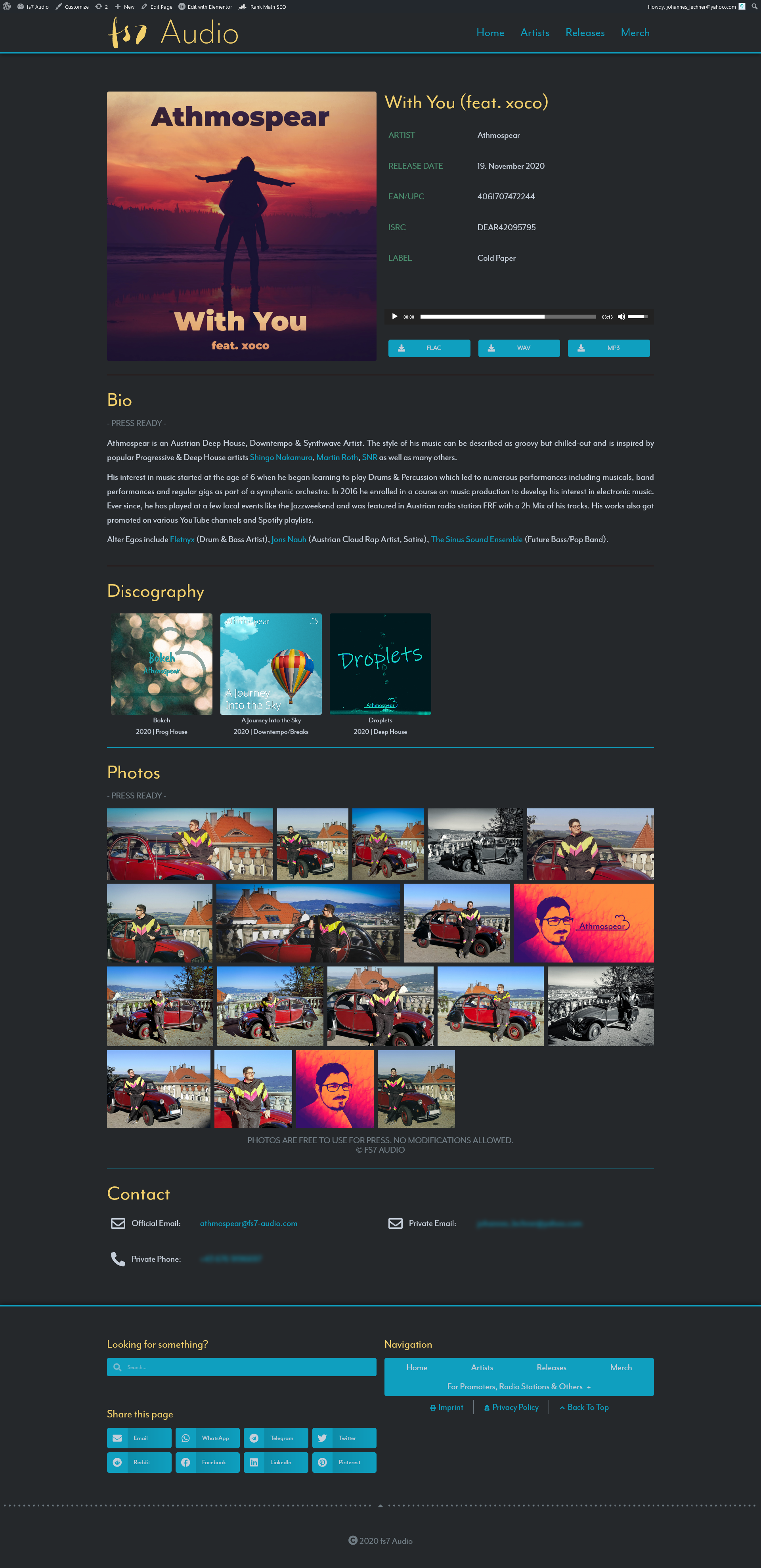
Convolutional networks include one or more convolutional layers. These layers are typically used for feature extraction. Stacking multiple on top of each other often can extract very detailed features. Depending on the input shape of the data, convolutional layers can be one- or multidimensional, but are usually 2D as they are mainly used for working with images. The feature extraction can be achieved by applying filters to the input data. The image below shows a very simple black and white (or pink & white) image with a size 3 filter that can detect vertical left-sided edges. The resulting image can then be shrinked down without losing as much data as reducing the original’s dimensions would.

In this project, all models containing convolutional layers are based off of WavGAN. For this cutting the samples down to a length of 16384 was necessary, as WavGAN only works with windows of this size. In detail, the two models consist of five convolutional layers, each followed by a leaky rectified linear unit activation function and one final dense layer afterwards. Both models were again trained for 700 epochs.
Convolutional Autoencoder
The convolutional autoencoder produces samples only in the general shape of a snare drum. There is an impact and a tail but like the small autoencoders, it is clicky. In contrast to the normal autoencoders, the whole sound is not noisy though but rather a ringing sound. The latent vector does change the sound but playing the sound to a third party would not result in them guessing that this should be a snare drum.
GAN
The generative adversarial network worked much better than the autoencoder. While still being far from a snare drum sound, it produced a continuous latent space with samples resembling the shape of a snare drum. The sound itself however very closely resembles a bitcrushed version of the original samples. It would be interesting to develop this further as the current results suggest that there is just something wrong with the layers, but the network takes very long to train which might be due to the need of a custom implementation of the train function.
Variational Autoencoder
Variational autoencoders are a sub-type of autoencoders. Their big difference to a vanilla autoencoder is the encoder’s last layer, the sampling layer. With this, variational autoencoders always provide a continuous latent space, which is much better for generative models than just to sample from what has been provided. This is achieved by having the encoder output two different vectors instead of one: one for standard deviation and one for the mean. This provides a distribution rather than a single point, leading to the decoder learning that an area is responsible for a feature and not a single sample.
Training the variational autoencoder was especially troublesome as it required a custom class with it’s own train step function. The difficulty with this type of model is that the right mix between reconstruction loss and kl loss has to be found, otherwise the model produces unhelpful results. The currently trained models all have a ramp up time of 30,000 batches until full effect of the kl loss. This value gets multiplied by a different actor depending on the model. The trained versions are with a factor of 0.01 (A), 0.001(B), as well as 0.0001(C). Model A produces a snare drum like sound, but is very metallic. Additionally instead of having a continuous latent space, the sample does not change at all. Model B produces a much better sample but still does not include much changes. The main changes are the volume of the sample as well as it getting a little bit more clicky towards the edges of the y axis. Model C has much more different sounds, but the continuity is more or less not present. In some areas the sample seems to get slightly filtered over one third of the vector’s axis but then rapidly changes the sound multiple times over the next 10%. But still, out of the three variational autoencoders model C produced the best results.
Next Steps
As I briefly mentioned before, this project will ultimately run on a web server which means the next steps will be deciding how to run this app. Since all of the project has been written in python so far Django would be a good solution. But since TensorFlow offers a JavaScript Library as well this is not the only possible way to go. You will find out more about this in the next semester.